Bibliography
Petros Maniatis
- Contents
- 1. Categories
- 2. Summaries
- 2.1 System Deadlocks (E.G. Coffman, Jr., M. J. Elphick and
A. Shoshani)
- 2.2 Fremont: A System for Discovering Network Characteristics and
Problems
- 2.3 Understanding SNMP MIBs
- 2.4 Limitations of the Kerberos Authentication System
- 2.5 The Spring Name Service
- 2.6 A Uniform Name Service for Spring's UNIX Environment
- 2.7 Persistence in the Spring system
- 2.8 Naming Policies in the Spring System
- 2.9 Subcontract: A Flexible Base for Distributed Programming
- 2.10 Understanding CORBA: The Common Object Request Broker Architecture
- 2.11 The Rio File Cache: Surviving Operating System Crashes
- 2.12 The Multics Virtual Memory: Concepts and Design
- 2.13 Recovery Management in Quicksilver
- 2.14 Operating System Support for Database Management
- 2.15 A NonStop Kernel
- 2.16 A New Page Table for 64-bit Address Spaces
- 2.17 Problems in supporting database transactions in an operating
system transaction manager
- 2.18 Monitors: An Operating System Structuring Concept (C. A. R. Hoare)
- 2.19 Communicating Sequential Processes
- 2.20 Application-Controlled Physical Memory using External
Page-Cache Management (Kieran Harty and David R. Cheriton)
- 2.21 Threads and Input/Output in the Synthesis Kernel (Henry
Massalin and Calton Pu)
- 2.22 Implementing Remote Procedure Calls (Andrew D. Birrell and
Bruce Jay Nelson)
- 2.23 Practical Considerations for Non-Blocking Concurrent Objects
(Brian N. Bershad)
- 2.24 Lightweight Remote Procedure Call (Brian N. Bershad, Thomas
E. Anderson, Edward D. Lazowska, Henry M. Levy
- 2.25 Experience with Processes and Monitors in Mesa (Butler W.
Lampson and David D. Redell)
- 2.26 On the Duality of Operating System Structures (Hugh C. Lauer
and Roger M. Needham)
- 2.27 A Fast File System for UNIX (McKusick, Marshall K. and Joy,
William N. and Leffler, Samuel J. and Fabry, Robert S.)
- 2.28 Vnodes: An architecture for multiple file system types in Sun
UNIX (Steven R. Kleiman)
- 2.29 Evolving the Vnode Interface (David S. H. Rosenthal)
- 2.30 Working Sets, Past and Present (Peter J. Denning)
- 2.31 The Design and Implementation of a Log-Structured File System
(Mendel Rosenblum and John K. Ousterhout)
- 2.32 Data Security (Dorothy E. Denning, Peter J. Denning)
- 2.33 Using Encryption for Authentication in Large Networks of
Computers (Roger M. Needham and Michael D. Schroeder)
- 2.34 An Attack on the Needham-Schroeder Public-Key Authentication
Protocol (Gavin Lowe)
- 2.35 The Zebra Striped Network File System (John H. Hartman, John
K. Ousterhout)
- 2.36 Serverless Network File Systems (Thomas E. Andersons, Michael
D. Dahlin, Jeanna M. Neefe, David A. Patterson, Drew S. Roselli, Randolph
Y. Wang)
- 2.37 Design and Implementation of the Sun Network Filesystem
(Russel Sandberg, David Goldberg, Steve Kleiman, Dan Walsh, Bob Lyon)
- 2.38 Disconnected Operation in the Coda File System (James
J. Kistler and M. Satyanarayanan
- 2.39 Replication in the Harp File System (Barbara Liskov, Sanjay
Ghemawat, Robert Gruber, Paul Johnson, Liuba Shrira, Michael Williams)
- 2.40 The MULTICS Input/Output System (R. J. Feiertag, E. I. Organick)
- 2.41 Weighted Voting for Replicated Data (David K. Gifford)
- 2.42 Input/Output Optimization and Disk Architectures: A Survey
(Alan Jay Smith)
- 2.43 Disco: Running Commodity Operating Systems on Scalable
Multiprocessors (Edouard Bugnion, Scott Devine, Mendel Rosenblum)
- 2.44 The LOCUS Distributed Operating System (Bruce Walker, Gerald
Popek, Robert English, Charles Kline, Greg Thiel)
- 2.45 VAXclusters: A Closely-Coupled Distributed System (Nancy
P. Kronenberg, Henry M. Levy, William D. Strecker)
- 2.46 Hive: Faults Containment for Shared-Memory Multiprocessors
(Chapin, John and Rosenblum, Mendel and Devine, Scott and Lahiri,
Tirthankar and Teodosiu, Dan and Gupta, Anoop)
- 2.47 Extensibility, Safety and Performance in the SPIN Operating
System (Bershad, Brian N. and Savage, Stefan and Pardyak, Przemys
 aw and
Sirer, Emin Gün and Fiuczynski, Marc E. and Becker, David and Chamgers,
Craig and Eggers, Susan)
aw and
Sirer, Emin Gün and Fiuczynski, Marc E. and Becker, David and Chamgers,
Craig and Eggers, Susan)
- 2.48 Automatic Inference of Models for Statistical Code Compression
(Christopher W. Fraser)
- 2.49 A Hardware Architecture for Implementing Protection Rings (Schroeder, Michael D. and Saltzer, Jerome H.)
- 2.50 TOPS: An Architecture for Telephony Over Packet Networks
(N. Anerousis and R. Gopalakrishnan and C.R. Kalmanek and A.E. Kaplan and
W.T. Marshall and P.P. Mishra and P.Z. Onufryk and K.K. Ramakrishnan and
C.J. Sreenan)
- 2.51 Adapting to Network and Client Variability via On-Demand
Dynamic Distillation (Armando Fox,and Steve Gribble and Eric A. Brewer and
Elan Amir)
- 2.52 The design and implementation of an intentional naming system
(William Adjie-Winoto, Elliot Schwartz, Hari Balakrishnan and Jeremy Lilley)
- 2.53 Names should mean What, not Where (James W. O'Toole and David
K. Gifford
- 2.54 A Model, Analysis, and Protocol Framework for Soft State-based
Communication (Suchitra Raman and Steven McCanne)
- 2.55 RFC 1546: Host Anycasting Service (C. Partridge and T. Mendez and W. Milliken)
- 2.56 A Survey of Active Network Research (David L. Tennenhouse,
Jonathan M. Smith, W. David Sincoskie, David J. Wetherall, Gary
J. Minden)
- 2.57 Active Names: Flexible Location and Transport of Wide-Area
Resources (Amin Vahdat, Michael Dahlin, Thomas Anderson, Amit Aggarwal)
- 2.58 Designing a Global Name Service (Butler W. Lampson)
- 2.59 Decentralizing a Global Naming Service for Improved
Performance and Fault Tolerance (David R. Cheriton and Timothy P. Mann)
- 2.60 Recommendation X.500: Data Networks and Open System
Communications - Directory
- 2.61 Descriptive Names in X.500 (Gerald W. Neufeld)
- 2.62 The Profile Naming Service (Larry L. Peterson)
- 2.63 Grapevine: An Exercise in Distributed Computing (Andrew
D. Birrell, Roy Levin, Roger M. Needham, Michael D. Schroeder)
- 2.64 Experience with Grapevine: The Growth of a Distributed System
(Michael D. Schroeder, Andrew D. Birrell and Roger M. Needham)
- 2.65 What's in a Name? (Peter G. Neumann)
- 2.66 Instant Messaging / Presence Protocol Requirements (Mark Day,
Sony Aggarwal, Gordon Mohr, Jesse Vincent)
- 2.67 A Model for Presence and Instant Messaging (Mark Day, Jonathan
Rosenberg and Hiroyasu Sugano)
- 2.68 IDentity Infrastructure Protocol (IDIP) (Akinori Iwakawa,
Shingo Fujimoto, David Marvit)
- 2.69 Identity Infrastructure and the Extended Individual (Tsuyoshi
'Go' Kanai, Shingo Fujimoto, Katherine Bretz, Dave Marvit, Yoji Khoda)
- 2.70 Introduction to Personal Communication on the Internet
(Christian Dreke)
- 2.71 Enterprise Identity Management within the Digital
Nervous System (Microsoft Corporation)
- 2.72 A Logic of Authentication (Michael Burrows and Martín Abadi)
- 2.73 Authentication in Distributed Systems: Theory and Practice
(Butler Lampson, Martín Abadi, Michael Burrows, Edward Wobber)
- 2.74 Development of the Domain Name System (Paul V. Mockapetris and
Kevin J. Dunlap)
- 2.75 Efficient and Flexible Location Management Techniques for
Wireless Communication Systems (Jan Jannink, Derek Lam, Jennifer Widom,
Donald C. Cox, Narayanan Shivakumar)
- 2.76 An Analysis of Wide-Area Name Server Traffic: A Study of the
Internet Domain Name System (Peter B. Danzig, Katia Obraczka, Anant Kumar)
- 2.77 RFC 1484: Using the OSI Directory to achieve User
Friendly Naming (OSI-DS 24 (v12))
(S. Hardcastle-Kille)
- 2.78 A Location Management Technique to Support Lifelong
Numbering in Personal Communications Services (Derek Lam and Yingwei Cui
and Donald C. Cox and Jennifer Widom)
- 2.79 Designing Directories in Distributed Systems: A Systematic
Framework (Chandy, K. Mani and Schooler, Eve M.)
- 2.80 Recommendation X.501: Data Networks and Open System
Communications - Directory: Models (ITU-T)
- 2.81 Global Internet Trust Register
- 3. Notes
- Bibliography
[116], [114], [115].
[89], [90], [79]
[28], [27]
[55]
[78]. [63] for the file system.
A first pass at an intentional name service and discovery protocol in
[1].
[7].
[5].
[61] for a general overview
of IDI. [58] for the current internet draft of the associated
protocols. [30] for Microsoft's Digital
Nervous System approach.
Self tuning in [74].
[53], [54]
[120](see page ![[*]](cross_ref_motif.gif) ).
).
[6].
[108] on vertical hand-offs,
[21] on performance of TCP. [41] for
distillation to facilitate wireless clients.
[70] on categorization and experiences.
[105] on VM/370.
A motivational/inspirational paper (particular on databases though) is [111].
[40] on component-based OSes.
[38] for a general
description. [60] for disk multiplexing. [15]
for SPIN.
[25] on V++.
[47] on KeyKOS.
[19] for Disco.
[117] on service infrastructure extensibility (via ``active
names'').
[35] is an early, general survey. Protection Rings in
[104]. The authoritative, seminal paper on authentication
algorithms in [80]. An attack against the Needham protocols
in [73].
[107] for a
position. [10] for its limitations (see page
).
Presentation of the DEC secure system infrastructure
for the DDSSA system (and associated theory) in [68].
[20] describes a logic of
authentication.
A paper-form global CA in [2].
[44]. Rio file cache in [24]. Quicksilver, a
transaction-based distributed system in [50]. The big database
picture on top of an OS in [110]. Tandem NonStop in
[8]. [72] for recovery and replication in
Harp. Fault containment in [23] for Hive.
Multics: [11] for the ``hardware'' side. [31] for
the software side. [112] for large page
tables. [49] for external page-cache managers.
[119] on LOCUS. [85] on the Information
Bus. [17,103] on Grapevine.
[16] on Modula-3 network objects.
[118] on CORBA, generally. [86] is a book on it
(see page ). [93] is a later
reference guide.
[76] for an overview. For the name service,
[95] and page , [81]
and page , [96] and page
. Persistence in [94] and page
. Subcontracting in [45] and
page .
[87] on host anycasting, useful for resource location or
intention-based routing.
[59] on the hierarchical Pleiades approach and
[66] on the online version of the same technique.
[67] is one of the first attacks
on Global Naming. [26] talks about the decentralization of
a global naming service. [77] Talks about the birth of
the DNS and [32] describes some DNS traffic analysis.
[84] is an old short thesis on
content-based naming. [1] on the Intentional Naming
System. [83] is a short thesis on the dangers of silly
naming systems.
[56] on the X.500 directory
service. [82] on creating a ``descriptive name system'' on
top of X.500 (or any hierarchical name system, for that matter).
[46] describes a way to implement guessable names within X.500.
[92] on the Profile Naming
Service.
[3] on scheduler activations. [23] on fault
containment.
Deadlocks in [29].
[9] capabilities/messages in DEMOS. Synthesis in
[74]. RPC, PARC style in [18].
Monitors, the Hoare approach in [51]. Non-blocking locks in [13].
[98] the original UNIX filesystem. [75] on
the Fast File System for UNIX. [99] on log-structured on
SPRITE.
[64] for v-nodes. [100] for their evolution.
[48] on the Zebra filesystem. [4] on
serverless filesystems. [63] for CODA. [72] for
Harp. [102] on the original NFS
design. [65] for VAXclusters. Weighted-voting in
replication in [43].
[39] on the first inklings of device drivers,
device-independent I/O interfaces, standard input/output, stream
redirection. [106] on a survey of disk optimization techniques.
[109].
[91] on SNMP MIBs (see page
).
[113] for a survey of '97 active network
research. [117] on the active names spin on mobile code.
[17] on the person-to-person messaging system in Grapevine.
The extended individual in [61]. Person-level routing in
[101]. The current, as of November 1999, IETF IMPP working
group model [34] and protocol
requirements [33]. The IETF identity infrastructure
in [58]. A blanket survey article in [37].
[88]
[12] from the CS368 class.
[42] on automatic model inference (decision trees for
compression).
2.1 System Deadlocks (E.G. Coffman, Jr., M. J. Elphick and
A. Shoshani)
The causes and repercussions of system deadlocks.
[29]Resources subject to deadlocks can be tangible things (like disk channels)
or abstractions (like a table or a process). There are resources that can
easily be preempted (like the CPU) or not so easily preempted (like the
disk). There are resources that imply the acquisition of other resources
(for example files imply having buffers through which to access those
files).
Conditions for a deadlock:
- Exclusive control of resources
- Resources can be claimed progressively; while new resources are vied
for, others already claimed are held vehemently
- Resource acquisition cannot be preempted
- Circular chains of required resources exist (i.e., A wants something
that B has, B wants something that C has, ... , Z wants something that A
has)
Havender's approach to preventing all of the above from happening at the
same time:
- Request all of the required resources at once. Don't proceed until
all have been granted. (Break the second condition above)
This can be costly, since some of the resources might only be needed
temporarily.
- If, while holding some resources, a resource request is denied, give
them all up and try again from scratch. (Break the third condition above)
This can be really inconvenient when used on inherently non-preemptible
tasks, like disk files.
- Impose an ordering in the types of resources, so that no circular
request orders can occur. (Break the last condition above).
This can be effective, although there can always be deadlocks caused among
resources of the same type, especially when the instance of the type is
not important.
The first condition above is considered unbreakable, since some things have
to be granted in an exclusive manner (disk blocks etc.)
Detecting the occurrence of a deadlock can be as simplistic as forming a
resource request graph occasionally and checking it for cycles, or as
educated as monitoring everything every task ever holds and requests and
deducing when the combination describes a deadlock.
Acting on a detected deadlock means forcibly reclaiming the resources held
by one or more of the participants. The author presents a simple,
cost-based scheme to pick which deadlocked tasks to abort, or even
minimize destructive aborts (i.e., aborts that involve non-preemptible
resources).
Another approach between making deadlocks impossible and just waiting
until they occur to fight them is searching ahead into the state space of
the system and identifying approaching deadlocks (for instance, two
current tasks seem to be likely to form a circular resource request
path). In those cases, through the scheduler for instance, the approaching
deadlock can be avoided by modifying current system behavior (in the above
example, making sure that the two dangerous tasks don't get scheduled in
an interleaved manner until the danger has passed).
In summary, there are three ways to deal with deadlocks:
- Deadlock Prevention This means making it impossible for
deadlocks to occur. Havender's approach above serves this purpose.
- Deadlock Detection This means identifying a currently
occurring deadlock and breaking it by taking action against the impasse.
- Deadlock Avoidance This means detecting the approach
of a deadlock and swaying the response of the system to avoid the danger.
r1, r2, ..., rs represent resource types. w1, w2,
..., ws represent the number of resources of each type. pij(t)denotes the number of resources of type rj allocated to task Tj at
time t. qij(t) denotes the number of resources of type rjrequested by Ti at time t. Matrices
P=((pij)) and
Q=((qij))define the allocation and request snapshots of the system, respectively,
and row vectors Pi and Qi are the allocation and request snapshots
for task Ti respectively.
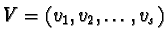 is the available
resources vector, where
is the available
resources vector, where
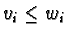 indicates the number of resources of
type ri currently available.
indicates the number of resources of
type ri currently available.
At every level, the algorithm picks a task that requires fewer resources
than those currently available. This means that, if all tasks take their
chance to reserve the resources they require, this task will have its
chance to advance and complete. After this determination, a task is marked
``able to progress'' and the resources it currently holds get added to the
pool of available resources (since, either way, it will release
them). When no more tasks can be marked ``able to progress'', and if there
still exists unmarked tasks, then the algorithm concludes that a deadlock
is in progress.
For an example, assume
W=(5,8,13), V=(2,1,1),
![$Q=\left[\begin{array}{ccc} 2 & 2 & 6 \\ 2 & 6 & 0 \\ 1 & 1 & 1
\end{array}\right]$](img4.gif) ,
and
,
and
![$P=\left[\begin{array}{ccc} 1 & 0 & 2 \\ 0 & 4 &
0 \\ 2 & 3 & 10\end{array}\right]$](img5.gif) .
In the beginning, the future available
resources vector is equal to V, or (2,1,1). The first pass of the
algorithm locates the third row of the Q matrix, (1,1,1), all of whose
elements are less than or equal to the future available
resources. Therefore, the third line of Q is marked, the future
available resources vector becomes
(1+2,3+1,10+1)=(3,4,11) and the
algorithm continues. Now the first row of Q fits the condition, so it is
now marked and the future available resources vector becomes
(3+1,4+0,11+2)=(4,4,13). Finally, the middle row of Q can satisfy the
marking condition and is also marked, leaving no unmarked rows and,
consequently, signifying the absence of any deadlocks.
.
In the beginning, the future available
resources vector is equal to V, or (2,1,1). The first pass of the
algorithm locates the third row of the Q matrix, (1,1,1), all of whose
elements are less than or equal to the future available
resources. Therefore, the third line of Q is marked, the future
available resources vector becomes
(1+2,3+1,10+1)=(3,4,11) and the
algorithm continues. Now the first row of Q fits the condition, so it is
now marked and the future available resources vector becomes
(3+1,4+0,11+2)=(4,4,13). Finally, the middle row of Q can satisfy the
marking condition and is also marked, leaving no unmarked rows and,
consequently, signifying the absence of any deadlocks.
If Q had been
![$\left[\begin{array}{ccc} 2 & 2 & 6 \\ 2 & 6 & 0 \\ 3 & 1 & 1
\end{array}\right]$](img6.gif) instead, then no line would be markable at the
beginning of the algorithm, and we would therefore be in a deadlock.
instead, then no line would be markable at the
beginning of the algorithm, and we would therefore be in a deadlock.
2.2 Fremont: A System for Discovering Network Characteristics and
Problems
[120]The basic idea is the parallel exploitation of multiple
sources of network information towards the same goal. A journal is created
using information drawn from ICMP, ARP, SNMP(future work), DNS, and
RIP. Although each method individually has results with limited coverage,
overlapping the results from multiple methods can cover the gaps.
Most techniques are fairly intuitive (pinging address ranges, broadcasting
pings, exploding TTLs as in traceroute, DNS zone transfers, ARPing subnet
ranges, snooping for ARP replies, etc.).
2.3 Understanding SNMP MIBs
[91]Network management handles 5 areas (according to the
OSI definition):
- Configuration Management
- Performance Management
- Fault Management
- Security Management
- Accounting
Extensibility is a bit of a joke in SNMPv1. You can either mirror a table
in the private subtree and use the same indices, or create a new pack of
indices for the extension.
Important considerations include how message delivery works (it's
unreliable, UDP-like), how actions should be separated between idempotent
and others, and how a request ``package'' should fit in one message, to
avoid unreliability due to fragments treated differently (i.e. a
fragmented packet, whose first fragment was dropped but the second wasn't
and so forth).
The whole trap scheme in SNMPv1 is very inflexible. I hope SNMPv2 works better.
2.4 Limitations of the Kerberos Authentication System
[10]Flaws deriving from the Project Athena environment.
- Kerberos prior to version 5 was a user-to-server protocol. It could
not be used as a host-to-host or user-to-user protocol.
- On multi-user machines, session keys are stored in files which can
be compromised (used without permission), if access control to the machine
is subverted. If I gain root access, I can use somebody else's session key
(if it's still available/current)
- Keys cannot be stored on /tmp, if it is a remote file system. In
that case, they are blatantly sent out over the net (BAD!)
- Tickets are bound to IP addresses. What happens with multi-homed
machines? What about mobility?
Protocol Flaws
- Replay attacks
Supposedly averted by authenticators. They have a very short lifetime
(typically 5 minutes). However, it is fairly easy to snoop an
authenticator and reuse it within its lifetime.
The only solution would be authenticator caching, to allow for
replays. That hasn't been implemented easily yet. For TCP, it's very
difficult, since servers are normally spawned by the main listener. Only
threading would work. For UDP, it would present problems with
application-level retransmissions. If the application could reconstruct
authenticators for each retransmission, the problem might be obviated.
- Time Service
Kerberos assumes that there exists an underlying authenticated time
service that can be used. This is not true however, not to mention that
even authenticated time servers could be subverted, off wire (by using a
fake radio transmitter, for instance). Instead, challenge/response sounds
like a better approach, proving (using a nonce) that each party in fact
possesses the session key. UDP would still be hard though (would need to
retain state per use).
- Passwords
It's relatively easy to exploit user weaknesses in choosing passwords to
make educated guesses. Passwords alone are not a good idea to determine a
client's key. Diffie/Hellman could be significantly better.
- Login spoofing
The same problem applies elsewhere as well. However, a good solution for
other cases (e.g.,. One Time Passwords) cannot be applied to Kerberos, since
an initial request is always encrypted by Kc.
- Inter-session chosen plaintext attacks
Message structure should be revised to prevent known-plaintext attacks.
- Session keys
They shouldn't be multi-session keys. They expose the system to
cryptanalysis.
- Ticket scope
Ticket forwarding imposes problems, since it assumes equal levels of trust
among all sites participating in the forwarding operation. Furthermore,
multi-realm authentication can have problems, especially in routing, since
there is not global realm name service.
Hardware Design
- To perform all key operations (and prevent keys from appearing in
hosts' main memories) a Kerberos-aware secure cryptographic box could be
used. This should not transmit keys in any way. I should only perform
cryptographic operations.
- A keystore, a secure storage facility, could be used to maintain key
databases, without understanding the protocol.
Certain portions of the Kerberos Protocol do not belong there, namely,
message encoding (something like ASN.1 or BER should be used instead) and
encryption mechanisms (let them be pluggable - the protocol should be
correct for any encryption mechanism).
Proposed changes:
- challenge/response instead of time-based authentication
- standard message encoding
- don't use passwords at the login. Use a one-way function of the
passwords given a random number instead (requires some sort of handheld
device to compute that)
- separate the encryption layer.
- use multi-session keys to provide true session keys
- support special-purpose hardware for cryptographic operations and
secure storage
- do not distribute tickets for users - authenticate initial exchange
- support optional extensions, like Diffie/Hellman.
An extremely interesting paper!
2.5 The Spring Name Service
[95]Name services can connect names to physical addresses of
objects, or to other identifiers (names) which are however easier to
resolve (for instance, from human-readable names to object IDs).
Issues in heterogeneous name spaces:
- Location
- How does the glue level get built. How,
that is, do the heterogeneous spaces fit together under a common
hierarchy (or will it be something other than a hierarchy?)
- Results
- A name service is normally a function from a name to a
physical identifier or other name. However, different name spaces have
different domains for the result of this function (i-nodes in file-system
directories, IP addresses in DNS, file descriptors in STREAMS). How do we
enable this diversified functionality under the same roof?
One solution is to make everything look like ``something''. In most cases,
this something is a file. So, give all objects a file interface (i.e.,
reads, writes, ioctls, and so on.). This is cumbersome, and in some cases
impossible. Did I mention esthetically scary?
- Dependency
- If the manager doesn't implements the name service, then
it knows how to handle persistent or transient object references and
names. In those cases however, the name service is not uniform. To make
the name service uniform, we must detach it from any one object manager,
and give it ways to handle persistence with the object managers whose
objects it names. Another way to do that is to resolve names to other data
IDs and then submit those IDs to the object managers for further
processing (as opposed to having an object representation).
In SPRING, name spaces and contexts (a generalization of a directory) are
first class objects; they can be shared and copied and duplicated and
destroyed and combined and stuff.
Object references are not persistent (you can't ``save'' an object
``pointer'' - you need to reacquire the pointer after execution is
resumed).
Access control is performed at the name server. If the object manager
wants to implement it itself (for instance, it doesn't trust the name
server) it can do that in addition to the name server's controls.
Names contain different fields with status information, version, and type
(C program or object code, and so on).
There are three kinds of persistence:
- Object state
- How the object manager stores the current state of an
object, when it is, in general, not active (i.e., not referenced by any
clients).
- Object access
- In SPRING, there are no persistent object pointers
(as in Clouds for instance), since not all objects will be persistent. In
Clouds, there are object IDs which remain persistent even when the object
moves around. They're pretty much names, without the ``readability'' of
those we customarily consider names.
- Name binding
- When an object has a name binding for it at a name
server, then it is persistent. Whether it's active or not is generally
determined by whether there are references to it or not. Otherwise, it can
be ``frozen'', i.e. turned into a data value (like a marshalled, flattened
version) and stored. This is normally what happens at the name server for
the object references of objects handled by object managers.
Access is only checked when trust boundaries are crossed (i.e. when we're
moving to a name server for a context that's not collocated with the
previously checked name server). If at some point the existing
authentication is not enough for the current name server (because we
crossed a trust boundary), the original
client is asked (through a raised exception) to authenticate itself with
the name server directly. Even when a context is passed between domains
owned by different principals, the exception will be raised when the
current credentials (in the capability within the context) don't match the
current principal. In those cases, the client owned by the different
principal will be contacted to authenticate itself directly.
Freezing and melting are done outside the object.
``Virtual worlds'' can be created, with slightly altered hierarchies (say
when a new release of the system is tested and only some of the
executables have changed). In those cases, domains can run with the
altered root context and carried name space, without any indication that
this is not the world that the rest of the domains run under.
2.6 A Uniform Name Service for Spring's UNIX Environment
[81]This is the conference version of the technical report shown in
[95], mainly focusing on the UNIX name space adaptation.
When a context (directory) comprises names from different scopes (i.e.,
the system/lib context of the village and the system/lib context of the
machine), the names are merged in order. More local instances are visible
first.
File system and NIS name service are not provided by Spring in the UNIX
emulation subsystem.
Instead of making all objects be treated as files (the Plan 9 approach),
objects that may be treated as files support the IO interface.
2.7 Persistence in the Spring system
[94]This is the conference paper on the persistence-related issues in
[95].
The issues in persistence and naming can be reduced to the following:
- What types of objects can be made persistent?
Persistent objects or persistent classes? Can persistent classes be
created? Can persistent objects be shared?
- How are object naming and storage services organized?
Are both persistent and transient name spaces supported? Are naming and
storage independent or conjoint?
- What kinds of inter-object references are supported?
Are inter-object reference types restricted? Can transient objects be
referenced in another object?
- How difficult is storage reclamation?
Which algorithm (Mark & Sweep, Reference Count)? Is storage reclamation
restricted in a single host?
The four approaches handled in the paper include:
- The Workspace Approach
The workspace approach (as seen in Smalltalk) allows programs to have a
persistent environment, and is implemented as a programming
environment. Objects and additional persistent object types (classes) can
be stored. However, references within the workspace of a program cannot be
externalized, therefore sharing is impossible.
The name space is flat and, in most cases, not easily manipulated. The
entire workspace is reflected into a single file in the
filesystem. Therefore, garbage collection is relatively easy (not to
mention that the entire workspace can be collected, by unlinking the file
it corresponds with).
Workspaces allow easy manipulation and all kinds of references to be
persistent, at the expense of sharing flexibility and programming language
selection.
- The UNIX approach
In UNIX, the only persistent objects are files, directories and symbolic
links. Other objects have to be transformed/stored inside a file to become
persistent. Sharing among processes/users is permitted, with some limited
access restrictions.
Transient name spaces are not supported in the basic UNIX system. Naming
and storage are conjoint in the file system.
The only objects that can contain references are directories. No transient
objects can be referenced in other objects.
Storage reclamation is handled through reference counting. The method
however can change to fit the object types stored.
UNIX supports sharing, as opposed to Workspaces. However, naming is very
limited and not at all uniform.
- Extended UNIX (Choices)
Many object types can be made persistent, in addition to files,
directories and symbolic links. Sharing is handled similarly to UNIX.
Transient name spaces are supported, but are handled through a different
interface. Naming and storage are combined.
Inter-object references are much more flexible than in UNIX. Still,
however, transient objects cannot be referred by persistent objects.
Storage reclamation uses reference counting; algorithms that can handled
cyclic structures need to be utilized. Inter-machine reclamation is
straightforward, since only symbolic links are allowed across machine
boundaries.
- General Approach
This approach combines the good features of all the above. Persistent
objects or classes are extensible and sharable.
Both persistent and transient name spaces are supported. The servers for
storage and naming are independent and separate.
References to other objects are unrestricted, and transient objects can be
referenced.
Storage reclamation is dependent on stored object types.
Transcription is the service used to transform an object's
representation on the client side or an object's data structure on the
implementation side into a form that can be used to reconstitute an object
in a different location or at a different time.
Time transcription can be tricky, since time related portions of the
object (for instance, references to transient objects) cannot be
stored. The following are related concepts:
- Pickling
It's transcription that's suitable for persistent storage. It happens at
the server implementing an object and is not directly visible to a client
through the object's interface.
Tough problems: following pointers in data structures, handling pointer
cycles, handling embedded objects, dealing with inheritance and unpickling
a pickled form as a base class of the original object.
- Freezing
Freezing occurs at the client side, and involves an object
representation. Freezing generates a freeze token that the client can use
later to reconstruct the object. The reconstructed object is not the same
as before being frozen, it shares however a large part of its state. The
implementation decides what will constitute a freeze token. A server may
well decide to return a pickled form of the object as a freeze token, or
an identifier that will help it reconstruct the object's state later (for
instance, the i-node of the file where the object's state has been stored).
Freezing invariably results in the object state being pickled.
A freeze token should be usable by clients other than the one that
initiated the freezing. Therefore, no client-specific data should be part
of the freeze token (for instance, no door identifiers).
Freezing and melting are performed by the freeze service of the manager of
an object. Each object has an Object Manager ID (OMID). This can be stored
along with a freeze token. The client that decides to melt this frozen
object can locate the freeze service by asking the name server for an
object manager with the stored OMID, and accessing its freeze service with
the stored freeze token.
Freeze tokens are forgeable. Therefore, the freeze service needs to be
authenticated.
Lost freeze token means lost object.
The name service is a good place to perform all freezing operations,
insulating clients from them. When no open references exist to an object
bound to a name in a name space, then the responsible name server freezes
the object reference, storing a name-to-freeze-token binding in stable
storage. When a client requests a resolution of a name bound to a frozen
object, then the name server melts the freeze-token transparently to the
client. Note that clients can always freeze objects directly.
This name service interposition between freeze and freezer, also
facilitates access controls: the name server checks all privileges
required from a client about to melt a freeze-token. Otherwise,
complicated security protocols would have to be observed, to transfer
melting privileges from client to client.
The melt operation can be made to start the corresponding object manager
(so that it can unpickle an object whose reference is being melted). This
can deal with object manager crashes, as well as managers that terminate
when they manage no active objects.
Different object require different freeze services:
- Data-like objects
The representation of the object is the freeze token. Such would be a
complex number.
- Transient objects
They can be frozen either by a per-machine transient object freeze
service, which stays up as long as the machine stays up, or by a library
inside the object server, which stays up as long as the object's manager
is up. The former requires some garbage collection (for those transient
objects whose manager has died).
- Externalizing
It is a transformation intended to create a copy of the object at a
different time or location, without any shared state with the original
object. Tar'ing a file system would be ``externalizing'' it.
Files become much less important components of an OS, now. Only
applications that need to handle their own storage more flexibly need use
files (for instance, to store freeze-tokens, or pickled objects).
Open Issues:
- Inter-object references
- What happens if we freeze an object that
contains a reference to another object? Do we freeze the other object and
stick the freeze token in the pickled object state? Do we just substitute
the object with a name?
- Garbage collection
- How do we delete frozen objects?
- Delete frozen objects when there are no more name bindings for them
would mean we'd have to search all name spaces, which can take a while.
- Have the clients of frozen objects ``ping'' them periodically would
incur a lot of pings for a name server, for instance. Furthermore, if a
name server got disconnected for a little while, and got back on-line, it
might find all its frozen objects deleted.
- Have an owner fro each frozen object that gets charged for resource
usage. This way, owners take the responsibility for keeping track of their
frozen objects and deleting them when they don't need them any more.
2.8 Naming Policies in the Spring System
[96]This is an elaboration of the naming policies in
Spring, as seen in the technical report([95]).
In the case of remote domain invocations, children inherit namespaces that
contain all ancestral local machines and villages, under the contexts with
names local_machine_X, local_village_X, where X is an integer
increasing down the inheritance path. The home contexts are those for
which X=0. The currently local contexts are those for which X is
maximum, and they are pointed at by the symbolic links local_machine
and local_village. The parent, however, does have the option to keep
the local contexts that the child inherits unchanged; in those cases, the
child executes in its parent's naming environment, though remotely.
2.9 Subcontract: A Flexible Base for Distributed Programming
[45]The gist is: Plug and play RPC mechanisms.
The general idea is that different objects elect what kind of RPC they
need to operate according to their specifications (i.e., replicated RPC,
atomic RPC, persistence or migration, etc.). This ``kind'' is embodied in
a subcontract associated with an object. All RPC operations go
through this subcontract.
Even in the cases where a different subcontract is expected, the mechanism
supports subcontract on-line discovery; thus, if a client needs to operate
on an object that supports a subcontract that hadn't been anticipated, the
correct subcontract can be found and loaded at run time.
The basic operations supported by subcontracts are:
The overhead over a more static approach is basically due to the
additional indirect calls, every time an object operation is used (first
to the object stubs and then to the subcontract). This is expense is
justified, according to the authors, by the added flexibility and the
enormous potential for extensibility, customization and optimization
without the change of the base system.
2.10 Understanding CORBA: The Common Object Request Broker Architecture
[86](1)CORBA was made to handle multiple architectures, multiple operating
systems, multiple data formats.
Connecting components together will happen again and again. Having a way
to do that without reinventing the wheel every time would be cool.
(1.4.2)Not only does CORBA handle the data translation between architectures etc.,
it also locates providers of the requested services.
2.11 The Rio File Cache: Surviving Operating System Crashes
[24]The basic idea is to improve filesystem performance and
reliability, by preserving memory across crashes, to achieve write-through
reliability with write-back performance. Crashes, not power outages, are
the main villain attacked.
Goal: Survive operating system crashes without writing data to
disk. They eliminate all reliability induced disk writes, by protecting
memory through a crash.
To protect the file buffer cache in kernel memory, they use TLB
protection: the buffer cache is read-only, until the kernel explicitly
wishes to change it. On CPUs that support direct use of physical memory,
bypassing the TLB, either that feature is disabled if possible, or
``sandboxing'' is used, by instrumenting the kernel to only allow writes,
if the accessed memory is outside the file cache or authorized to be
written. This is much slower than just disabling TLB bypasses.
To restore the buffer cache, an in-memory registry is maintained
and used, where all buffers get tagged with their defining metadata
(physical memory address, device number and i-node number, file offset and
size). The registry only imposes 40/8192 or 0.5% of the buffer size space
overhead. Before the VM and FS are booted during a warm reboot, memory is
dumped into the swap partition. Also at this point, metadata are restored
on disk, making sure the filesystem is intact. When the system has
completely booted, a user-level process analyzes the memory dump and
restores the file cache.
Effects:
- No reliability-induced writes needed
- Metadata updates must be carefully ordered
- Atomic updates to the registry are feasible
To test reliability, they use synthetic, injected kernel faults: bit
flips, instruction mashing, high-level scrambling (variable instantiation
eliminations, overruns in bcopy, switches of loop conditions, futzing with
loop base pointers, ...). To detect corruption, they checksum all buffers
and go through them to look for inconsistencies after the crash.
Rio is neat: much faster than other means of protection (like turning all
writes into write-throughs). More reliable than pure write through.
Catch: it requires that the CPU do not erase the memory across a reset!
2.12 The Multics Virtual Memory: Concepts and Design
[11]This paper is mainly used as an indication of how
difficult things would be if we still had physical memory limitations. The
creators of MULTICS went to amazing lengths to make sure that no physical
memory is wasted on stuff that's not immediately needed.
Some VM facts:
- There is a different page table per segment. A segment can have up
to 64 pages, and since each page is 1024 words long, each segment can be
up to 64K words long.
- A portion of physical memory is reserved for page tables only.
- The ``i-nodes'' of segments on the filesystem need to be modified
whenever a segment is activated in the system (the address of the page
table assigned to the segment is recorded in it). Doesn't sound too smart,
although it might be justified by the constraints of the time
frame. Recovering from a crash must be a lot of fun, with active switches
left on all over the place in the file system.
- The number of page tables (i.e., ``(PT,ASTE) pairs'') substantially
exceeds the number of pageable blocks of core. Funky! More pagetables than
pages. Those were strange times...
Terminology:
- Make Segment Known It means associating a segment pathname
with a segment number. If some other segment has made a target segment
known, this task avoids ``reacquainting'' the process with the same
segment. Intra-process scope.
- Activate Segment It means allocating a page table for a
segment and copying the segment map into the active segment table. The
segment on secondary storage is marked to point to the associated active segment
table entry in physical memory. Extra-process scope.
- Connect Segment It means connecting a segment's descriptor to
an active page table. In other words, if the segment is already in memory,
brought by some other process, connection finds it and uses
it. Inter-process scope.
2.13 Recovery Management in Quicksilver
[50] The key contribution of the system is the exposure of the
low-level transaction mechanisms to servers, as opposed to the use of
high-level transaction interfaces only. Therefore, servers can direct
their own recovery, using these mechanisms.
Single-host transaction operations are handled locally. Only Transaction
Managers need communicate with other hosts. Minimization of exchanged
network messages was the motivating concern. The hierarchy is
fault-tolerant and can be made more efficient, in that coordinators can be
replicated (to avoid single-point failure), and coordinators can migrate,
to minimize the distance between a coordinator and its participants.
Some refinements of two-phase commit protocols have been used. For
instance, participants that do not modify recoverable resources, can be
excluded from phase two for efficiency.
2.14 Operating System Support for Database Management
[110] Gripes about the way in which operating systems
support DBMSs.
This is the earliest place I've seen the need for extensibility in
filesystem caching (or as Stonebraker calls it, ``Buffer Pool
Management''). Problems:
- Somewhat slower
- Buffer replacement algorithm isn't controlled by the DBMS (and the
DB does know exactly what it needs)
- Prefetches can only detect sequential access. Again, the DBMS knows
how it should prefetch instead
- Writeback onto disk of buffers is done independently. The order and
the atomicity across multiple buffers is important in transactions.
DBMSs use structured basic objects, as opposed to the unstructured
character arrays (i.e., files), that normal OSes use, through their
filesystems.
- Files grow one block at a time. Blocks can be distributed all over
the disk's surface. Extent-based file systems are preferable.
- Two many tree structures to find an object: the one used by the
indexing scheme of the DBMS, one for the file directory and one for the
file blocks (through the i-nodes). One tree for all three functions would
suffice.
He also argues here that an OS would be better off providing database
abstractions at a lower level and implementing character abstractions on
top of those, instead of the other way around (which is the current
practice, pretty much).
The next gripe argues UNIX imposes the use of a DB process-per-user, as
opposed to having a server that accepts messages. I don't quite see how
this applies any more (he only considers pipes the only IPC mechanisms
available). Should that have been the case, the problems would have been:
- Blocking for I/O leads to a large process (an entire DBMS) to be
swapped, which can be costly.
- To preserve consistency, locks have to be placed on the buffer pool
by competing DBMS processes. If a process gets scheduled out while holding
such a lock, a convoy of waiters on that lock forms.
The alternative of having one server and multiple clients has its
problems, too.
- Either the server needs to do its own multitasking, or take requests
in a FIFO manner, resulting in potentially long response times (especially
when, say, a long request precedes lots of short requests).
- Resources might end up underutilized, especially when there are
multiple disks.
- The ``have a pool of servers servicing requests'' approach is very
similar to having a process-per-user.
- Finally, having disk servers which service requests from the single
server sounds attractive, but message overheads (at the time of writing)
can be prohibitive here too.
As far as consistency is concerned, the two points apparently suggested
above are:
- A specific set of buffers in the file cache has to be flushed upon
commit. Control on that must be provided.
- If crash recovery is independent of transaction dependencies, then
the order in which a transaction is performed might alter the results of
the recovery operation after a crash.
Again, things either need to be done by the OS (if the performance issues
can be resolved), or all duplicated by the DBMS.
Gripes on memory mapped files
- large sequential files (stored sequentially) have to have large page
tables, which don't provide any additional information; a starting point
and a length would have sufficed.
- Buffering is a problem here, too.
The size of the page table seems to have grown in orders of magnitude
since then, but still exists.
In other words, OS extensibility is sorely needed.
2.15 A NonStop Kernel
[8] Wow! I think I just read an early description of a
Remote Procedure Call, before it was called that! There is an interesting
approach to canceling a request or a response, though.
The interprocessor protocol looks a lot like an early TCP clone. No slow
start or congestion avoidance stuff is there, obviously, since the
interprocessor buses are fairly reliable (less than one fault in a month
reported). Processors broadcast a heartbeat every second. If two
successive heartbeats are skipped by a processor (and detected by others,
obviously), the processor is deemed dead.
The concept of process pairs is also brought up. Every process is backed
by a checkpoint process, which receives status updated after every
message operation of the primary. If the primary process dies, the backup
becomes the primary and picks up where the dead one left off. To deal with
non-idempotent requests handled by dead servers, a buffer of responses is
retained, so that already answered requests can be answered again without
recomputing a response.
2.16 A New Page Table for 64-bit Address Spaces
[112] A very interesting, dense assortment of information on
page table and TLB technologies and how they scale up to larger address
spaces than they were designed for.
First, different page table organizations are presented:
- Linear page tables are just huge arrays containing one entry per
page. For a large address space, the page table might have to be paged,
too. For something like a 64-bit address space, with 4kb pages, it might
take 6 levels of paging to get to an actual word in memory. These are
great in terms of locality, but the sheer size of the table can be
prohibitive.
- Forward-mapped page tables split a virtual address into fields of
different sizes, which are used as indices in a large n-ary tree of page
table pointer entries. This is a similar approach to linear page tables,
with the difference that the branching factor of the tree can be variable
here, and intermediate nodes can reside in physical memory. Intermediate
nodes don't need to be entire pages, as opposed to those in multi-level
linear page tables.
- Hashed page tables follow an approach close to ``inverted'' page
tables, where the size of the search structure is comparable to the size
of the physical memory, not the size of the virtual memory. A virtual
address is hashed to locate a hash bucket, where the page table entry
might reside. These are great for sparsely populated address spaces, but
have a lot of space overhead per page table entry.
The paper introduces the concept of clustered page tables, which combine
the benefits of closely-accessible neighboring pages of linear page tables
and those of relatively-low overhead for sparsely populated address spaces
of hashed page tables. The idea is that every node in the hashed page
table corresponds to more than one PTEs (2, 4, 8, ...), for adjacent
virtual pages. Therefore, within a hash node, the linear metaphor is used,
but the hashed metaphor is used to locate a batch of PTEs. Clustered
page tables exploit the apparent ``burstiness'' of address spaces, where
large objects occupying more than one page are sparsely scattered in the
address space. Therefore, a cluster can hold the page entries for such
large objects with relatively low overhead.
The paper then goes on to present the hardware approach to larger virtual
address spaces: TLBs that support superpages and sub-blocks.
- A superpage is a virtually and physically aligned block of (2, 4, 8,
...) pages, that can be accessed by a single TLB entry.
- A completely-sub-blocked page is a similarly aggregated batch of
pages. Each participating page, however, can be mapped to independent
physical pages, i.e., the mapping of the batch onto physical memory need
not be contiguous.
- A partially-sub-blocked page is actually a superpage, some of whose
individual pages might be missing. In other words, every individual page
has to occupy the same page offset into the physical mapping of its batch
that it occupies in its virtual mapping.
Page table support for such extended TLBs is the suggested:
- replication of extended PTEs to cover the entire area of the page
table that a beefed-up TLB entry covers.
- +
- A single miss causes a mapping for the entire batch to be
loaded, i.e., reduced TLB miss frequency at no cost.
- -
- Page tables don't get reduced in size.
- -
- Updates are more complex (the same information is stored in
multiple locations).
- Multiple page tables, one per size. Search the most common one
first, and on a miss move to the next most common, etc.
- -
- TLB miss handlers would get much much slower, unless most misses
involve the first page size.
- -/+
- Page table size is reduced, but more page tables are needed.
- Linear Intermediate Nodes. Use a multiple-level tree. Internal tree
nodes can be used as PTEs for a superpage the size of all PTEs this
internal node represents.
- -
- Only unwieldy sizes supported (eg. 2MB, 1GB, 512GB, 256TB, 64PB).
- +
- No significant time cost in TLB miss handling for support of
multiple sizes.
- Superpage-index hashing. Use the tag of the superpage and store PTEs
for its components into the hash bucket.
- -
- Longer hash chains mean longer access time.
- -
- Superpages with sizes larger than that of the index would still
need replication or some other mechanism to be handled.
Support for partial-sub-blocking is easier and more worthwhile. Using
clustered page tables gives a better solution for all three extensions.
- A clustered page table could serve complete-sub-blocking
directly (they use the exact same concept).
- Partial sub-blocking with the same blocking factor as the cluster is
also easy to support. Instead of having an entry per base page in the hash
node, a single entry with all the valid bits is used. As far as the hash
table is concerned, the chain length is exactly the same.
- Superpaging is also supported, best when the only super page is the
one with the same size as the cluster. Smaller superpages could also be
supported, using a size field in the PTEs. However, searches could take
longer, since a successful tag match with a missing mapping could also
mean that a another matching tag exists down the chain, with a different
page size.
2.17 Problems in supporting database transactions in an operating
system transaction manager
[111] Yet another paper motivating OS extensibility. OSes
provide transaction and recovery support, but not of the kind that
Databases want. Here's the canonical version of it all (i.e.,
database-unspecific).
Three big issues exist:
- Granularity OSes support a certain granularity (page, for
instance), but applications need another (record or relation, for
instance). This can yield lower efficiency (especially when the
discrepancy among the two granularities is great).
- Functionality OSes invariably provide less functionality than
what applications need (except after the late '80s, early 90's, when the
converse became true: more functionality was supported than anyone was
ever going to need). For instance, if the OS transaction manager only
offers a specific kind of locking mechanism (from the beginning of a
transaction till the bitter end), but the database also needs something of
the shorter-term variety, then there's a problem.
- Extensibility OSes define events and actions to be taken on
those events. In some cases, those events and/or the associated actions
are not enough; new code needs to be defined and executed with kernel
privileges. In this example, the action that ``reverses'' an event (i.e.,
the undo of an event) should be customizable by applications, so that they
can use their own semantics in the framework provided by the
kernel. This opens up huge issues with security, trust and so on.
Solutions? Here we go:
- Extend everything. Let applications plug in code anywhere (and
deal with the slew of problems arising). It's what the authors would love
to happen. This is where the field went in the '90s.
- Tailor applications to what the OS is offering, and do it
well, too. In some cases, it cannot be done, which further motivates the
previous approach.
- Use what the OS is offering, but make up for what's missing.
In this case (transaction and recovery of databases), it's the worst
approach, since it involves a lot of complex interoperations of different
modules of code. It has worked in other cases.
- Ignore the OS and provide your own functionality. It has been
done extensively, especially by database management systems. A waste of
human effort.
- Make your functionality the OS functionality and let other
applications deal. Not quite a solution; the ``other applications'' would
then write their own instantiation of this paper.
2.18 Monitors: An Operating System Structuring Concept (C. A. R. Hoare)
[51] A straightforward paper, introducing an implementation of
monitors (using the infamous ``Hoare semantics'').
Interesting here are some ideas on inserting some smarts into the
mechanism that picks which waiter on a condition variable to wake up. The
idea is to assign a fixed priority to a wait operation. This priority will
be used to schedule wake ups when the condition variable is signaled.
A very useful set of rules Hoare describes in this concept was good enough
that I'm going to quote them here:
- 1.
- Never seek to make an optimal decision; merely seek to avoid
persistently pessimal decisions.
- 2.
- Do not seek to present the user with a virtual machine which is
better than the actual hardware; merely seek to pass on the speed, size
and flat unopinionated structure of a simple hardware design.
- 3.
- Use preemptive techniques in preference to non-preemptive ones where
possible.
- 4.
- Use ``grain of time'' methods to secure independence of scheduling
strategies.
- 5.
- Keep a low variance (as well as a low mean) on waiting times.
- 6.
- Avoid fixed priorities; instead, try to ensure that every program in
the system makes reasonably steady progress. In particular, avoid
indefinite overtaking.
- 7.
- Ensure that when demand for resources outstrips the supply, the
behavior of the scheduler is satisfactory.
- 8.
- Make rules for the correct and sensible use of monitor calls, and
assume that user programs will obey them. Any checking which is necessary
should be done not by a central shared monitor, but rather by an algorithm
local to each process executing a user program.
2.19 Communicating Sequential Processes
[52] Hoare presents a language where input and output and
parallelism are basic primitives, and describes how a number of simple
exercises would be accomplished on this language. He concludes by
justifying some of his design choices.
The language consists of
- Guarded commands, i.e., commands with a condition and a body where
the body is executed only when the condition executes successfully.
- Parallel commands, i.e., commands comprising multiple independent
subcommands, all of which begin in parallel.
- Clearly named input and output commands. ``Clearly'' here means that
both source and destination of a communication command are specific and
unambiguous.
- Alternative commands, which are commands comprising multiple guarded
commands; the guard most closely fulfilled is the one picked by the
scheduler to result in the execution of a body.
- Repetitive commands, which are pretty much iterated alternative
commands.
It is a cute and elegant enough language, with very powerful
constructs. There is still some criticism though:
- Explicit Naming It's not fully justified, but it does make
difficult the construction of libraries. The use of port names, to which
processes can attach their inputs or outputs could mitigate the problem,
without changing the semantics.
- Unbounded process activation In all process array examples,
the bounds of the arrays are static. The reasons is that this is to run on
a real machine, with a finite number of processors, so having a bound
makes this language more practical.
- Fairness Exactly how a scheduler is going to pick that one
command among many in an alternative command, which doesn't preclude
progress is left open. It sounds like an interesting exercise to figure
out how to do that, without building a very slow system.
A very enjoyable paper altogether, with some interesting insights on
language construction in a rather different domain.
Easy to do, but I thought I should...
S(i:1..100)::
*[ S(i-1)?least()->S(0)!noneleft()
[]n:integer;S(i-1)?has(n)->S(0)!false
[]n:integer;S(i-1)?insert(n)->
loaded:boolean;loaded:=true;
*[ loaded;S(i-1)?least()->
S(i+1)!least();
[ l:integer;S(i+1)?l->S(i-1)!n;n:=l
[]S(i+1)?noneleft()->S(i-1)!n;loaded:=false
]
[]loaded;m:integer;S(i-1)?has(m)->
[ m<=n->S(0)!(m=n)
[]m>n->S(i+1)!has(m)
]
[]loaded;m:integer;S(i-1)?insert(m)->
[ m<n->S(i+n)!insert(n);n:=m
[]m=n->skip
[]m>n->S(i+n)!insert(m)
]
]
]
2.20 Application-Controlled Physical Memory using External
Page-Cache Management (Kieran Harty and David R. Cheriton)
Exo-virtual memory.
[49]The title says it all. Some applications need to play with
their virtual memory. Examples are described in Stonebraker's rant in
[110], in the case of databases. For another example, in
the case of large scientific simulations, the application knows exactly
how memory is going to be accessed (for instance, sequentially);
therefore, it can best determine how page replacement is to
proceed. Finally, applications can make educated decisions about
space/time tradeoffs, based on how much physical memory is available to
them.
To accomplish that goal, the authors have modified the kernel of V++ to
associate an external page-cache manager with each segment of a process's
address space. This manager gets a number of pages from the system's
manager and deals with them as it sees fit, to react to pages demanded
from the associated application.
An interesting side note, explained for real elsewhere, mentions the
allocation of memory according to an economic model of fixed
supply. Application-controlled page-cache managers can only maintain
memory as long as they can afford it. They get a steady income, get
penalized for saving, and are subject to exchange rates with I/O traffic.
2.21 Threads and Input/Output in the Synthesis Kernel (Henry
Massalin and Calton Pu)
[74]The main ideas: code synthesis and reduced
synchronization inside the system.
The principle of frugality says that ``we should use the least
powerful solution to a given problem''.
Code synthesis is used to specialize and optimize system interfaces for
their intended use. Especially frequently traversed interfaces (like the
system calls interface) can save a lot of computation being specialized
and made short enough for their associated thread. The basic disadvantage
is that every thread, or every thread group, needs to store its special
versions of common code, after its creation.
Reduced synchronization shares some of its motivation from specialization,
above. The idea is that, instead of using data structures that support
synchronization, even when synchronization is not needed, a
non-synchronized version of them is created and used when the extra
functionality is not needed. Other ways of reducing synchronization is
code isolation, procedure chaining and optimistic synchronization.
Code isolation transforms algorithms so that synchronization is
unnecessary. For instance, in a regular data structure supporting a put and a get, a different piece of the metadata in the structure
is writable by the put and a different one is writable by the get. So locking is not necessary. Obviously, this works if there's only
one process running get at a time, and only one process running put at a time, which is also where specialization is
applied.
Procedure Chaining replaces context switches among threads in the
same address space with simple procedure calls. This is done by changing
the return addresses in the stack. Optimistic Synchronization can
be seen, for example, in context switching, when a thread that doesn't use
the floating point facilities of the processor does not save floating
point registers when scheduled out. Floating point instructions cause an
illegal instruction fault when first used, at which point the context
switch code is make less optimistic, i.e., starts saving floating point
registers as well.
2.22 Implementing Remote Procedure Calls (Andrew D. Birrell and
Bruce Jay Nelson)
[18]Local procedure call semantics works well, so extending
it to work remotely is the next step.
Before RPC, programming on a distributed environment was too
complicated. The authors' major aim was to provide a more conducive
programming environment for remote computation. Other aims were to make
this environment adequately efficient, and reasonably secure.
Local procedure semantics is followed as closely as possible. Client and
server stubs are created automatically from the interface descriptions.
A client binds to a particular interface (the type) and a particular
instance (a machine and a process exporting that interface). The instance
can be ``any''. The name server stores interfaces and their instances and
returns the appropriate one when asked. Exported interfaces contain entry
points of each procedure, a unique id for the instance and a call id,
which identifies a request and its response, as well as their order.
Interfaces are capabilities. Access controls on the naming service
exporting them transfers on to them.
The transport protocol is reliable (ACKs, timeouts, retransmissions, keep
alives for long calls). Time based identifiers are used to distinguish
responses from reset servers or duplicates. Exceptions are raised on
network glitches. The protocol is tuned for short exchanges of small
arguments. For larger exchanges it uses a bulk-transfer-like protocol,
which is not as efficient as the state of the art bulk-protocol (to avoid
complexity).
Exception handling is defined in the interface. Exceptions are passed
back, in the place of return packets.
To optimize server response, idle server processes are standing by. If a
server is expecting a call, it gets it. Otherwise, the call is dispatched
to an idle server.
Lots of neat ideas that have been widely used since.
2.23 Practical Considerations for Non-Blocking Concurrent Objects
(Brian N. Bershad)
[13]Main target: shared-memory multiprocessors.
Consistency can be guaranteed by mutex critical sections or non-blocking
concurrent objects. Non-blocking objects have no (actually, only short)
queues, i.e. are not vulnerable to convoys, priority inversion, deadlocks.
Basic problems:
- compare-and-swap(CAS) doesn't always exist
- performance in the presence of contention
Synthesizing CAS using locks, when no hardware CAS exists, is not
non-blocking. Roll-out solves that, by always releasing the lock on
preemption. The code resumes at a different point, depending on where it
was when it was preempted. This mechanism seems to be there only for the
CAS mock-up. Roll-forward finishes up on preemption and it's harder to
implement (for instance, what do you do on page faults?). Software CAS is
good for more complex conditions and multibyte swaps. Roll-out can be
prevented from progressing and is vulnerable to processor failure.
How do we synchronize to mock-up a CAS? Synchronization operations are
becoming costlier in faster architectures.
Spinlocks cause a lot of bus activity on all processors: when the lock is
released, everyone tries to acquire it.
Queuelocks turn lock contention into a relay race. Each contender waits
for a single holder to release the lock. Therefore, every sync operation
is a successful operation. They are more complex to implement and geared
towards lock-based mechanisms. However, ``success'' here means that
- 1.
- the lock was acquired, and
- 2.
- that the CAS succeeded
This is not the case in non-blocking synchronization. Unfortunately, for a
sequence of threads trying to accomplish a similar update on a shared data
item, only one will succeed, and all else will fail, after they've waited
to acquire the lock for the CAS mockup.
A general fix is to only request a lock when the CAS is likely to succeed,
by checking the CAS value, before acquire-lock (something like
``compare*-compare-and-swap'').
[14]RPC is cool as a message passing mechanism. It's
designed to work cross-machine. However, the most common case is still
single-machine calls (as shown in studies of V, taos, sunos/nfs). The
authors attempt to create an optimized version of RPC.
Locally RPC overheads come from:
- stubs
- They need to be general, but are not often used fully.
- copies across domains
- access authorization
- queueing
- context switches
- command parsing in the callee's dispatcher
Optimizations have been proposed but are not far enough.
LRPC calls go through the kernel, which validates the authorization and
creates the link to the callee.
Clerks deal with interface exports. Interfaces are exported in structures
much resembling virtual method tables. There's one in every domain. It
registers with a name server. Procedures in an interface are given a
descriptor, which contains an entry pointer in the server's domain and a
list of argument stacks. A-stacks are mapped read/write in both domains,
so no copying is needed to transfer arguments from caller to
callee. A-stacks can even be shared among procedures of the same
interface. Linkage records contain the return domain and address for an
A-stack. The whole thing is contained in a binding object, which is
unforgeable, much like a capability.
E-stacks are managed by the server. They are associated with an A-stack
until the server runs out and reclaims one. E-stacks and A-stacks adhere
to the Module procedure calling conventions, which separate argument from
execution stacks.
More complicated stubs are done in a more conventional RPC way.
On multiprocessors, domains are cached on idle processors, so that
redundant context switches are avoided.
In general, arguments are copied around fewer times. All kernel copies are
eliminated. An extra copy is done when parameter immutability needs to be
ensured.
Multiprocessor speedup is almost perfect, because locking of shared data
structures is minimized.
2.25 Experience with Processes and Monitors in Mesa (Butler W.
Lampson and David D. Redell)
[69]This is an introduction to the monitor construct,
as implemented on the Pilot workstation and in the Mesa programming
language. Pilot was intended to be a multiprogrammed single-user
machine. Therefore, a lot of protection-oriented issues are dismissed as
only producible through malicious mechanisms.
The authors didn't want to solve communication with message passing,
mainly because it didn't mesh well with their programming language of
choice, Mesa. After all, Lauer and Needham argued that message passing and
process-oriented structures are, effectively, duals of each other.
To guarantee consistency, they did not want to use a non-preemptive
scheduling mechanism, mainly because the whole idea of paging (and the
necessary page faults) breaks non-preemption, anyway, and besides, in that
case, multiprogramming would have to be done only through voluntary
relinquishments of the processor. This is, by common agreement, very
awkward.
Processes in Mesa are very easy to create. In fact, any procedure can be
invoked as a separate process; in other words, procedures can be called
synchronously or asynchronously, with explicit support in the language.
Process creation in that context (especially since it shares the address
space and the program text) is very cheap, making arbitrarily frequent
process creations a viable approach. The only difference between
synchronous and asynchronous processes comes in the context of exception
handling, since detached procedures are, in fact, the root in the
exception handling pyramid. Perhaps exceptions could be passed on to the
creator of a process, but that would probably be too big a hassle, worse
even when the creator has itself terminated.
Monitors have entry procedures (which need to reserve the lock before
they're executed), internal procedures (which can only be called from
inside an entry or internal procedure, and don't touch the lock), and
external procedures, which don't require the lock. Things get a bit hairy
when an internal or entry procedure contains a call into a different
monitor's procedures. The lock of the first monitor doesn't get freed, in
which case, if the second monitor causes the caller to sleep, the first
monitor becomes bound on a sleeping process. Alternatives exist to some
extent, but it's a generally difficult situation, which makes the whole
monitor concept less than perfect.
To make sharing of large, cellular structures more efficient, the monitor
mechanism has to allow for finer locking (the default case deals at the
whole Mesa module's scale). An idea is to have monitored records (such as
a node in a linked list, for instance), allow locking at that
scale. Obviously, when futzing with the structural integrity of the entire
construct (front and back pointers, etc., or counters), perhaps the global
lock should also be acquired.
Mesa monitors/condition variables define a different semantics (differing
from C.A.R. Hoare's initial suggestion). A notify (which Hoare called
``signal'') doesn't relinquish control of the CPU immediately. It merely
is a hint that any waiters on a condition variable might start thinking
about waking up. When they do, they explicitly need to check the condition
on which they slept, mainly because it might still not be favorable to
their causes (e.g., a different process might have entered the monitor
first, before the former waiter woke up). This may result in fewer context
switches, though not necessarily in the face of congestion.
The authors have also defined an additional operation on a condition
variable, called ``broadcast''. This wakes up all processes waiting on a
condition variable. It can be invaluable in cases where a single condition
change might satisfy the requirements of multiple waiters.
The authors define the concept of a naked notify. This is only performed
by devices, via interrupt handlers. Since a device probably cannot go
through the whole monitor entry story every time it needs to produce an
interrupt (because others might be following), it just does an unprotected
notify (``naked''). This can cause race conditions, since it might occur
between the time that a real process has checked a condition and has
decided to sleep. In effect, it might never be awakened again. A
lock-free synchronization construct could be useful here (like
compare-and-swap).
2.26 On the Duality of Operating System Structures (Hugh C. Lauer
and Roger M. Needham)
[71]There are two schools of thought on building systems with
synchronization: message oriented systems and procedure oriented
systems. The authors propose a correspondence, element to element, of the
two that renders them duals of each other, thereby making the question
moot.
- message oriented systems:
relatively static, large processes; specific communication paths; the
process is the resource manager.
Synchronization occurs at the message queues. Operations are serialized
there.
The canonical resource manager is a huge case statement.
- procedure oriented systems:
resources are protected by shared data structures; consistency is ensured
by locks etc. Processes are short lived and numerous.
Synchronization occurs at mutex lock queues.
The canonical resource manager is a monitor.
A correspondence between elements of each class has been found. For
instance, an asynchronous message-reply pair corresponds to forking out a
process with a procedure call and waiting on the result.
The authors go even further, to suggest that the duality preserves
performance as well. They break up performance in 3 components, all across
which the duality is maintained:
- 1.
- execution times of the ``meat'' of each program
unaffected by duality
- 2.
- overhead of primitives
they assert it without proof; they seem to miss however that process
creation is much costlier than procedure calls (perhaps in a threading
context the differences are not as pronounced)
- 3.
- queueing times and scheduling
scheduling should be mapped across in a straightforward way, since queues
are involved in either model.
The conclusion is that the model or the performance considerations thereof
shouldn't influence how a decision is made on which one to choose. Rather,
considerations like which one is easier to implement could be used
instead.
2.27 A Fast File System for UNIX (McKusick, Marshall K. and Joy,
William N. and Leffler, Samuel J. and Fabry, Robert S.)
[75]Problems with the ``traditional'' UNIX file system:
- i-nodes are separated from their data.
- blocks are allocated randomly, sometimes resulting in long seeks per
512-byte transfer.
- free blocks were organized in a linked list. The list's locality
quality deteriorated after use.
First wave of changes:
- increase of block size to 1024
- fsck for maintaining reliability
The real FFS had the following enhancements
- superblock replicated at well known locations. Each replica is
located on a different platter, cylinder or track.
- another increase in block size: 4096k
- disk is divided in cylinder groups, each containing its own i-nodes,
datablocks, block map etc. This ensures that access locality can be
maintained to some extent. It also means that some free space needs to be
reserved to allow this to happen.
- access locality is also maintained through optimal rotational
placement of consecutive blocks on disk. The characteristics of the disk
are part of the info in the superblock and the cylinder summary info.
- allocation policies (local with full info/global with partial info)
are used to decide where an i-node or data block will go.
- blocks are split into fragments to minimize waste through
fragmentation. Fragments can only be used at the end of a file. This means
that growing files with trailing fragments might need to copy those
fragments into new blocks.
- instead of a free list, a block map is used. In fact, this is a
fragment map.
Additional Functionality, which wasn't coming as a direct response to
shortcomings in the traditional Unix File System
- long file names
- advisory locks.
- symlinks
- ``atomic'' rename
- quotas
2.28 Vnodes: An architecture for multiple file system types in Sun
UNIX (Steven R. Kleiman)
[64]The design goals for this extensions were:
- to split FS-dependent from FS-independnt functionality
- to provide an interface between the two
- support popular FSes of the time (in terms of the offered
functionality)
The implementation uses an object-oriented approach: operation vectors.
The Vnode is a virtual equivalent to an i-node. Vfs is a virtual mount
entry. Different filesystems can appear in the same hierarchy without
specialization.
2.29 Evolving the Vnode Interface (David S. H. Rosenthal)
[100]The general idea is pushing the vnode
concept[64] further, by giving its object oriented model
inheritance.
16 trillion levels of indirection, since v-nodes can now stack, fan out,
tree... All operations have to be called through a whole chain of
invocations (one to go to the Vnode, then to go to the top of the stack,
then to follow the head of the stack one level down and then to indirect
through the operations vector).
The description sounds cool structurally, but I'd have to see more
convincing performance results before making judgment.
2.30 Working Sets, Past and Present (Peter J. Denning)
[36]A painful paper, with no less than 126 references...
A program's working set is the collection of pages it has recently
referenced.
A bit unclear what exactly Saltzer's Problem is. A box with a knob we turn
to tune performance? Not very clear. The knob here is the control
parameter  ,
which governs the tradeoff between resident set size
and longer times between faults.
,
which governs the tradeoff between resident set size
and longer times between faults.
The swapping curve plots f(x), where x is the mean resident set size
and f is the rate of page faults. The lifetime curve plots
g(x)=1/f(x), i.e., the mean number of references between page
faults. The global max of g(x)/x is the best a policy can do. Simple
models for g fail to capture the behavior of real programs.
A restatement of the policy: The working set policy is that under
which a program's resident set is the collection of pages that have been
referenced in the last
time ticks.
A generalization deals with the ``retention cost'' of a segment, accumulated
since its prior reference. The generalized working set policy retains
pages whose retention cost doesn't exceed a certain limit.
Simple program behavior models fail to capture phase transitions (they
assume locality characteristics remain constant). ``slow-drift'' models
are a compromise: they assumed a continuous degradation of locality. Real
measurements proved these inadequate as well. In practice, slow-drift can
only account for program behavior within short phases of its execution.
The phase/transition model specifies that long high-locality periods are
separated from each other by short, erratic transition periods. Phases
cover about 98% of the time. Transitions cause about 50% of the page
faults.
Network queueing models have been used to determine which is the optimal
``multiprogramming level'' (load) of a paging system. Studies have shown that
the ``L=S criterion'' (when the time between faults L is equal to the time
it takes to service a fault), or the ``50% criterion'' (keeping disk
utilization to 50%) yield close approximations to the optimal load.
The problem with the above criteria is that they attempt to apply across
all programs, even when for example the max lifetime doesn't exceed the
page-in time. Space-time minimization per job should be the optimality
criterion. Load controls (limits on the load of the system) have been used
to limit the drop-off in CPU utilization when thrashing ensues.
The basic components of a dispatcher are:
- the scheduler, which activates or deactivates jobs and allots them a
time to use the CPU.
- the memory policy manages which pages will remain in memory, either
using local criteria (like WS) or global (like LRU).
- the load controller adjusts the limit on the load of the system
based on current conditions, globally or locally.
For local policies like WS, the selection of
for each job is a
daunting task. However, it was found that for (allegedly) typical program
mixes, a global WS
yields performance within 10% of the
optimum. Furthermore, WS performs the exact same sequence of page faults
as the optimal lookahead method, displaced only by the lookahead time. It
is very close to optimal, when fully tuned.
2.31 The Design and Implementation of a Log-Structured File System
(Mendel Rosenblum and John K. Ousterhout)
[99] Main assumption: read requests are easily satisfiable
by using main memory; optimize for writes and many small files. As memory
becomes more abundant and less expensive, more of it can be available as a
file cache (for both reads and writes).
Gripes against older FSes:
- too many seeks
- too many synchronous writes(metadata)
To fix this, writes are performed sequentially in a log. Once enough write
data are available, a single write operation into the log is initiated,
requiring only one seek. This includes data and meta-data blocks.
Major issues:
- how do we retrieve data?
- how do we find consecutive empty blocks?
The log is the main storage structure, i.e., it's not temporary. So, every
time a file changes, it and its i-node get written in the log. An in-memory
i-node map points to the current location of all i-nodes. This map gets
checkpointed on disk periodically.
For writes in the log to be fast enough, contiguous long writes must be
possible. The disk is split into 512k segments. Segments are always
completely overwritten, if changed at all. Segments with little live data
are copied over in a compacted form.
Liveness is determined by checking to see if a datablock is pointed to by
the appropriate pointer in the associated i-node (the i-node # and the block
# for each block in the segment is stored in the segment's summary).
The ``cleaner'' is the component that compacts live data to open up more
contiguous space (more empty segments) for the log. It attempts to only
read in segments with a low liveness ratio, to minimize the cost of
cleaning. In addition to the above criterion, recently modified blocks are
considered likely to change soon, i.e., not worth compacting. So, the age
of the live blocks in a segment is also taken under consideration when
deciding whether to clean or not to clean.
Crash recovery uses checkpoints and roll forward. A checkpoint contains
the i-node map, the segment map and a time stamp. Given this initial info,
segment summary blocks are used to roll-forward the FS with operations
that happened after the checkpoint.
LFS is slower than a traditional fs only when reading sequentially a file
written randomly.
Main performance factors: cleaning(about 25%), rw(75%) In UNIX it's
seeking(90%) and rw(70%).
2.32 Data Security (Dorothy E. Denning, Peter J. Denning)
[35] Internal security (as opposed to external: armed
guards, fire protection and such) is mainly focused on the following:
- access controls
- It relies on being able to identify principals securely
(authentication).
- It makes temporary observation awkward.
- The privilege database is extremely sensitive and should be kept out
of reach.
There are two major design patterns:
- Access control lists
- Capabilities
- flow controls
They limit the information flow to prevent leaks from secret to less
secure classification. Once you're at class A, you can't talk to a lesser
class. This scheme incurs severe overclassification, since all principals
end up going up in classification. It doesn't model the world (for
instance, NDAs temporarily increase a person's classification for a
certain domain, with specific penalties in case of privilege incursion)
To fix, info flow must be deduced (which input affects which
output). Detect covert channels. This is very very hard.
- inference controls
Restricted private info can be inferred from unrestricted aggregate info:
ask controlled question when part of the answer is known (trackers).
Solution: reduce accuracy of answers, use random samples.
- encryption
It helps with authentication, guards against eavesdropping.
2.33 Using Encryption for Authentication in Large Networks of
Computers (Roger M. Needham and Michael D. Schroeder)
[80] Seminal paper on the basic authentication protocols
used today. It covers both shared key ciphers and public key ciphers.
They're dealing with encryption and authentication protocols, in three
contexts:
- Interactive encrypted communication
- One-way encrypted communication
- Signed communication
In all cases, there are two phases: one during which principals request a
key from a trusted authentication server and one during which they
authenticate themselves with each other. Nonces (one-use-only identifiers)
are embedded in most messages that might be prone to replay attacks.
The basic, shared key, Needham-Schroeder protocol between two principals,
A and B, and a trusted authentication server AS are as follows:
- 1.
-
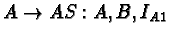
IA1 is to avoid having a bad person send us an older response by the
AS, which it (the bad person) has had time to decrypt and play with.
- 2.
-
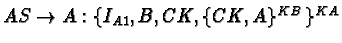
Both IA1 and B are returned, to make sure this is the response to
the request above, and not just any replayed response.
- 3.
-

- 4.
-
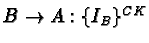
This is to certify that the real A is on the other side, not just a
replayed stream.
- 5.
-
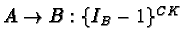
Obviously, this couldn't be
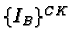 ,
since that could just as
easily be replayed...
,
since that could just as
easily be replayed...
The same scheme is followed for public/secret key encryption
algorithms. Given that A and B have already located the public keys of
each other, here's how they initiate a conversation.
- 1.
-
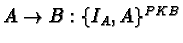
- 2.
-
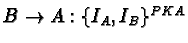
- 3.
-
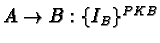
Unfortunately, the protocol above has been found to be
broken. Specifically, in the end, right after step , Bthinks he's definitely talking to A, although there's no guarantee of
that. Gavin Lowe presented the first mention of the problem in
[73].
2.34 An Attack on the Needham-Schroeder Public-Key Authentication
Protocol (Gavin Lowe)
[73] The author presents a way in which the public-key
authentication protocol presented in [80] can be subverted
with a man-in-the-middle attack. The general idea is that A starts a
conversation with the intruder. The intruder can make someone else (B in
the example below) think he's talking to A.
- 1.
-
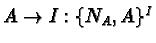
A starts a normal authentication conversation with I, the bad guy.
- 2.
-
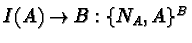
I decrypts the message by A, since it was addressed to it. Then, Iimpersonating A, replays the message, encrypted with B's public key.
- 3.
-
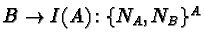
B naively responds with its own nonce. The message is intercepted by
I.
- 4.
-
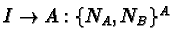
I just replays the message as received to A.
- 5.
-
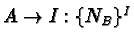
A replies as normal, exposing the nonce to I.
- 6.
-
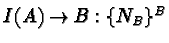
Now I resends the nonce encrypted with B's public key. For all intents
and purposes, B thinks it's talking to A now, although A thinks it's
talking to I.
The protocol can be fixed against this attack, by including the identity
of B in the middle step of the protocol, so that A cannot be tricked
into colluding with I.
- 1.
-
- 2.
-
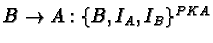
- 3.
-
2.35 The Zebra Striped Network File System (John H. Hartman, John
K. Ousterhout)
[48] The general idea is to do striping across multiple
storage servers, with parity, just like RAID. Zebra globs writes together,
just like LFS [99].
Striping helps with
- load balancing (load is distributed among all storage servers)
- parity for recovery (if a disk dies, the remaining ones can recover
its contents)
- parity for availability (if a disk is down, the remaining ones can
be used to recover the missing contents)
- higher throughput (aggregate bandwidth is higher than that of
individual disks)
Striping is not done per file, which would limit the benefit (since the
file would need to be chopped to tiny pieces), but per log
segment. Per-file striping causes a discontinuity in the way small and
large files are handled. If, on the other hand, small files are stored in
fewer servers than the full array, then the space overhead of parity
becomes huge.
The LFS approach was borrowed. Here, logging is used between a client and
its fileservers (as opposed to the original LFS case, where logging was
used between a client and its disk). Each filesystem client uses its own
log and stripes its log segments, instead of the individual files.
File meta-data are managed centrally by a file manager. The logs contain
only data blocks. The file manager also deals with cache coherence,
namespace management. It has to be contacted for all opens and closes. It
has a local "shadow" file for each file accessible through the Zebra
filesystem. The local shadow file contains block pointers and such.
Segments are reclaimed by a stripe cleaner, similar to a segment cleaner
in LFS. Instead of using segment summaries, as in LFS, the cleaner keeps
track of usage information in stripe status files, which it keeps as
normal ZebraFS files.
Deltas contain meta-information that clients write into their logs; deltas
don't contain data. However, deltas are also read by the file manager, so
that it can manage meta-data accordingly.
Recovery needs to cover:
- client crashes (in which case, a partially stored stripe might be
regenerated from a parity fragment, or discarded)
- storage server crashes (in which case, either a fragment has been
partially stored or some fragments should be stored but haven't; checksums
help find incomplete fragments and parity helps reconstruct missed
fragments)
- file manager crashes (in which case, metadata might not be up to speed
given the current deltas; delta replay is used to bring the meta data up
to speed, assisted by checkpoints of covered deltas per client).
- cleaner crashes (in which case, the cleaner status for each client's
stripes might be out of date; log replays are used here as well).
The only critical resource is the file manager. Any single crash by
another component can be dealt with on-line, without reducing
availability. Recovery of any single failure can occur while the system is
running.
Some points where things might not be as rosy:
- Small files are only collectively benefited. That is, if you're only
dealing with few small files, you still have the problem with LFS not
being the best paradigm to use.
- Striping introduces a higher error rate (more disks that can fail),
which is then reduced back by parity striping units. It's unclear whether
there's a net decrease in error rate.
- The larger the number of servers, the larger the stripe size has to be to
make the fragment size efficient, i.e., more buffering is needed than in
the single-host case. That's why stripe groups where introduced in the
evolution of ZebraFS (see [4])
2.36 Serverless Network File Systems (Thomas E. Andersons, Michael
D. Dahlin, Jeanna M. Neefe, David A. Patterson, Drew S. Roselli, Randolph
Y. Wang)
[4] The general idea is: ZebraFS [48]
completely decentralized. Any participant can take over the role of any
failed component. Also, xFS employs cooperative caching, to use
participant's memory as a global file cache.
Major assumption: a cluster of cooperating workstations (NoW), whose
kernels trust each other completely. A cool application of this is using a
NoW as a fast NFS server.
Three main problems solved:
- scalable, distributed metadata; scalable, distributed cache
consistency management, reconfigurability after failure
- scalable subgrouping to avoid excessive distribution
- scalable log cleaning
Metadata are handled by managers. A shared, globally replicated manager
map assigns a metadata manager to a file. The assignment of files to
managers is done through assigning different bit areas of the inumber to
different managers. New files are given appropriate index numbers so they
are managed by a manager living on the same node that created them.
Each metadata manager has an IMAP to locate the blocks to its files. In
fact, an IMAP entry contains the disk location of the file's i-node, which
contains the block addresses or the addresses of indirect blocks.
Storage servers are split into stripe groups. A stripe is split among
fewer storage servers than all those available, to make sure that stripe
fragments don't turn too small or, conversely, that clients don't have to
buffer enormous amounts of data. Each stripe group has its own
parity. Therefore, simultaneous storage server failures in different
groups can be recovered from. Also, clients can write to different stripe
groups at full speed at the same time.
i-nodes are only cached at the managers, so that the manager doesn't get
bypassed when a local cache can't satisfy a request. This was decided so
that cooperative caching could always be preferred to disk access. Caching
is done per file block, not per file and follows the write-invalidate
protocol.
Recovery is accomplished through checkpointing, roll-forward and
distributed consensus for membership list recovery.
2.37 Design and Implementation of the Sun Network Filesystem
(Russel Sandberg, David Goldberg, Steve Kleiman, Dan Walsh, Bob Lyon)
[102] This is about one of the most popular remote
filesystem on the Unix platform.
Design goals:
- no dependence on OS (allow for heterogeneous client accesses)
- crash recovery
- access transparency
- UNIX fs semantics
Built on top of SunRPC. Calls are idempotent, so lack of UDP reliability
is no problem; retries can be used safely. "Stateless" means that all
necessary information for a call is given inside the parameter list. The
protocol is stateless, not its components (i.e., the server keeps state
for the clients and each client keeps state for the server).
The fhandle(file handle) represents the server's FS-specific identifier
for a file at a client, and it's opaque as far as the client is concerned.
The file access protocol (NFS) is different from the filesystem mount
protocol. Mount protocols need OS-specific information to put a
client-server association together, whereas the file access protocol is
OS-unspecific.
Statelessness implies synchronous disk operations on the server. In other
words, all modifications on the server are flushed before a call returns.
i-nodes are versioned, to avoid i-node aliasing (i.e., using a stale file
handle on an i-node that has been recycled).
NFS motivated the design of v-nodes, as a way to provide uniform access to
different filesystems inside the kernel.
Both protocols (NFS and MOUNT) were implemented in user space. The kernel
vnode implementation of NFS jumped out of the kernel to have requests
completed.
The hard issues on which the paper comments are, strangely enough, those
which still haven't been fixed (give or take one or two).
- The whole issue of access control and root squelching. The same
hacky solution they found (making root less powerful than normal users) is
still in place.
- Concurrent access. Still a mess...
- Locking.
- Open file semantics. Since the server can't maintain state, it can't
just open a file, unlink it and keep on using the file pointer. They fixed
this with a hack.
- Modification times and time skew. Still a problem, although not
exclusive to NFS.
- Performance: Horrendous, since everything is going through RPC, XDR
and the whole shebang of intermediate layers of stuff.
All in all, a great idea but we should have moved along quite a bit since.
2.38 Disconnected Operation in the Coda File System (James
J. Kistler and M. Satyanarayanan
[63] Main goal: highly available operation for a network
file system, even in the face of disconnection.
Workload is balanced at the granularity of subtrees. High availability is
achieved through:
- replication
- disconnected use
Caching is done on whole files. This simplifies disconnected operation and
allows for more straightforward failure modes. Clients are given most
functionality, to promote scalability.
The contents of the cache, in the face of disconnection, can be determined
by the user, in the same way this is done when a user copies interesting
files on a laptop before leaving a network access point and then
reintegrates them back into the file repository, on reconnection.
When disconnected, the pessimistic approach would be to enforce
consistency, by requiring an a priori acquisition of a shared or exclusive
lock for access. In the case of involuntary disconnection, this is
unrealistic. The optimistic approach, which is the one taken by Coda,
allows all updates and hopes no conflicts will ensue; when conflicts do
arise, they are resolved upon reconnection.
System calls are intercepted through v-nodes and serviced by a user level
cache daemon (Venus). Venus can be in any one of three states:
- When connected, Venus is hoarding (i.e., accumulating files in its
cache). It has to deal with updating its file versions (since others might
also be modifying cached files), with cache space management and with
keeping certain files, in which the user has expressed explicit interest,
around.
- When disconnected, it emulates normal operation, by using its cache
to satisfy file requests. It also fakes some of the functionality that
normally only servers provide (i.e., assigning a new file ID and
such). Results of this usurped functionality have to be revalidated by
real servers upon reconnection. Cache misses can either block until
reconnection, or return an error code. Mutating operations are logged, so
that they can be replayed upon reconnection. A caching intricacy during
disconnection is that the cache has to be maintained across crashes (since
it's what the user perceives as the emulation of the servers). Therefore,
it uses recoverable virtual memory for the meta-data, which
enforces transaction semantics and provides recovery across failures.
- When reconnected, it briefly goes through the reintegration phase,
where it deals with update conflicts. The entire log of mutating
operations, as assembled during disconnection is shipped to all
servers. There it is replayed inside a single transaction, and applied to
all referenced files. If reintegration succeeds (i.e., there are no
conflicts), the log is purged and Venus goes back to hoarding
mode. Otherwise, a user utility can be used on the log to selectively
apply it. Conflicts of interest are only write/write conflicts. Each file
has a version number (storeID) associated with it. If the version numbers
between the log entry and the server copy of the file are compatible,
there is no conflict. In the case of directories, conflicts can sometimes
be resolved.
2.39 Replication in the Harp File System (Barbara Liskov, Sanjay
Ghemawat, Robert Gruber, Paul Johnson, Liuba Shrira, Michael Williams)
[72] Basic idea is replicating storage servers through a
primary storage manager. Furthermore, writes are aggregated through the
use of the write-behind strategy, in conjunction with a UPS, to make sure
that power failures don't kill the volatile write log.
Harp is not a file system. Rather, it's a replication extension written
using the VFS interface. It strives to maintain Unix and NFS file system
semantics.
Every file is assigned a server group. A server group consists of a
primary server, a bunch of backups and a bunch of "witnesses". When any of
the primary or backups is disconnected, or partitioned away, a new view of
the server group is created, where one of the witnesses is promoted to
serve as backup. Witnesses only store event logs (i.e., sequences of
modifications on the file system). Logs are played back during recovery to
resynchronize the state of the file system.
Modifications on the file system, as stored in event logs, are applied by
an applier kernel thread. This thread goes through the event log and calls
the appropriate local filesystem calls to have them propagated to disk.
2.40 The MULTICS Input/Output System (R. J. Feiertag, E. I. Organick)
[39] One of the earliest suggestions of device drivers,
device-independent I/O interfaces, standard I/O, redirection.
Device-independent I/O was made possible by the memory mapped nature of
Multics. Once a segment was made known (no matter what device it resided
on), it could be accessed independently of its implementation or
capabilities.
Device-specific data manipulations are done inside the ``Device Interface
Module'', which is pretty much an object-oriented device driver in current
terms. Its interface even provided for device-specific commands, similar
to ioctls.
A very exciting paper to read, given the context in which it was written.
2.41 Weighted Voting for Replicated Data (David K. Gifford)
[43] Replication of files in a distributed,
transaction-enabled environment.
The main points are:
- Every replica i is assigned a number ni of votes.
- Every transaction collects r votes to be able to read a file, and
w votes to be able to write the file.
- A read quorum and a write quorum must always overlap, i.e.,
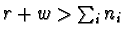
- Read/write quorum overlap guarantees that every read quorum contains
a current replica of the file (i.e., one with the latest modifications in
it).
- Current replicas of a file are determined using version numbers,
which are increase every time a transaction starts writing into a file.
Votes are assigned to a replica depending on the reliability of the host
on which a replica resides. A very very reliable machine causes replicas
living in it to have many votes. When r for instance is lower than the
number of votes of a very reliable replica, then reading that replica
successfully is good enough. Obviously, reliability must also cover
consistency in this regard.
Caches of a file can be maintained close to a client, by creating a copy
with 0 votes. They don't participate in the consistency considerations,
except as far as their version number is concerned.
Updates to the vote configuration are supported exactly like a normal file
modification (every replica contains a directory of all other replicas,
which is 1-1 associated with the version number of the replica).
2.42 Input/Output Optimization and Disk Architectures: A Survey
(Alan Jay Smith)
[106] A very interesting survey, supported by a large number of
large enterprise installations. The issues brought up are somewhat
outdated, but a large portion thereof still have a great significance.
Why is I/O an issue? Why do we want it optimized?
- Gap between main memory and fast disk access times is enormous
(about 5-6 orders of magnitude).
- CPU has to do a lot of stuff to issue and get a response to an I/O
request
Small block size on disk means:
- +
- smaller buffers are required
- +
- buffers are quicker to transfer, once they're located
- -
- data are scattered into more blocks, which have a greater
probability of being in more different places on disk
- -
- the physical inter-block gaps on disk waste space
- Related data should be placed close together
- Frequently used data should be near the middle of the disk surface
(i.e., between the center and the edge)
- Concurrently used datasets should be on different disks
Evaluation criteria:
- Minimize mean access time
- Minimize variance of the I/O access time
- Avoid discriminations against some data placed unfavorably; avoid starvation
Main algorithms used: Scan, SSTF (shortest seek time first), cyclical
Scan, others.
In some large systems, disk arms hardly move (because the disk is
exclusively used for a particular kind of sequential application), so such
matters don't really count. It doesn't seem that many current systems
follow this pattern.
- Requests for different blocks in the same track can be ordered with
Shortest Seek Time First. Also, a different queue may be set up for
different sectors, so requests are serviced first-come-first-serve on the
queue coming under the head.
- Sequential accesses can't be handled without overhead in the CPU, so
skip sector allocation allows for continuous access.
- Track switching can be handled with spiraling, i.e., starting
adjacent sectors at different angular positions.
- On fixed arm systems, frequently accessed blocks can be replicated
at different angular positions, to be better reachable.
On sequential access, it can increase performance by a lot.
The farther ahead a sequential run is, the more likely is to jump into a
different run soon. So, adjust the prefetched size according to the age of
a run.
- Block Allocation
- -
- Random allocation is very bad for sequential access. No
prefetching is possible
- +
- No external fragmentation to talk about (though we still have
internal fragmentation)
- Extent Allocation
- -
- Degrades over time
- +
- It can exhibit better sequential access and it makes contiguous
allocation easier.
For both schemes, compaction can be a good general solution, although it
- is slow,
- requires exclusive access to the data repository
- imposes a whole slew of updates when data structures refer to disk
blocks on which a data item resides
Frequently used data, especially meta-data, should be pinned in memory for
faster access.
- Fixed block disks. They're guaranteed some minimum capacity (since
we know how much the interblock gaps cost us). They're easier to search
and control.
- Non-mechanical secondary storage: Powered RAM ``disks''
- Smarter I/O controllers. They impose fewer interrupts and have more
autonomy to plan things efficiently
- More on-disk buffering.
2.43 Disco: Running Commodity Operating Systems on Scalable
Multiprocessors (Edouard Bugnion, Scott Devine, Mendel Rosenblum)
[19] The return of the Virtual Machines.
The goal is to take current operating systems to shared memory
multiprocessors. Also, allow fixed-parallelism operating systems (like NT)
to share more resources.
Main technique: virtualize everything (CPUs, memory, I/O devices). The
virtualization layer is much smaller than a complete operating system, so
it's also faster to develop and less prone to bugs. Fault containment
comes naturally since each virtual machine can fail independently of
others running alongside it (although more is needed for hardware fault
containment, e.g., cellular DISCO).
The traditional problems with virtual machines have been:
- Overhead: Real CPUs have to be emulated, privileged instructions and
devices virtualized and so on. Each copy of the operating system has to
reside separately in every virtual machine's memory, and so do separate
buffer caches. Similarly, multiple filesystems have to eaxist for each
virtual machine.
- Resource management. How do you multiplex a single physical device
among multiple entities that consider it exclusively theirs? Decisions
have to be made without higher-level information from the OSes (is the CPU
doing something useful, or just idle-spinning?).
- Sharing, communication. How do you take advantage that all these
different systems run on the same machine to increase functionality?
Each virtual CPU is treated like a process in a conventional operating
system. A table is maintained of most recent register contents (including
privileged registers), TLB entries, so that virtual CPUs can resume where
they left off, when scheduled on a real CPU. Virtual kernels are executed
in supervisor mode, which is not quite as powerful as kernel
mode in the MIPS architecture. When a privileged instruction is attempted
by the virtual kernel, the trap is handled by Disco which changes the
appropriate virtual privileged registers and jumps to the trap hanlder of
the virtual kernel.
There are three levels of memory in DISCO:
- virtual (within a virtual machine - each process has memory starting
at 0, but address 0 is mapped to a non-zero phyhsical address)
- physical (within a virtual CPU - each virtual CPU has memory
starting at 0, but address 0 is mapped to a non-zero machine address)
- machine (honest-to-goodness physical memory)
When a virtual TLB is reloaded, we replace the mapping from virtual memory
to physical memory with a mapping from virtual to machine memory. Any
subsequent accesses to virtual memory get correctly translated to the
corresponding machine memory without additional overhead. The ``page
table'' that translates physical memory page numbers to machine page
numbers is the pmap, which is keps for each virtual machine. The
pmap also contains back pointers from physical memory page numbers to
their corresponding virtual page numbers, to assist with invalidations
when a page is take away from the virtual machine.
In MIPS, kernel code lives in an unmapped address space. Since this
bypasses the TLB, it makes virtualization either impossible, or too slow
(as would be the case if every single instruction had to be emulated to
fix memory references). Therefore, OSes on MIPS have to be slightly
modified to put their kernels in mapped memory (this is, in fact, a change
on the Operating System ITSELF, however other architectures don't have
such problems with memory mapping, so this shouldn't be a problem for
Disco on them).
Virtual machines suffer more TLB misses than when the OS runs
standalone. This is because the kernel also has to go through the
TLB. Also, TLB misses are more expensive, since traps have to be
emulated. To alleviate the problem, Disco maintains a second level,
software TLB, practically extending the size of virtual TLBs. So, some
virtual TLB misses are never sent to the reload code, since they're
satisfied under the virtual machine.
Under the virtual machines, the NUMA-ness of the system is hidden from the
operating systems. Pages migrate or get duplicated transparently to
improve performance. Page access trends are measured through the cache
miss counting facility provided by FLASH. When a page needs to migrate,
the virtual TLB entries are invalidated and the page gets
copied. Similarly, virtual TLB entries are downgraded to read share a page
across multiple real processors. To find the right TLB entries, a
memmap is maintained, mapping machine pages to sets of virtual
machine/virtual address pointers.
I/O devices are virtualized through Disco-aware device drivers installed
into the virtual OSes. Each device defines a monitor call command,
which is used to pass all arguments to a device command to the monitor
in one fell swoop. These calls perform virtual to machine memory
translations for DMA requests, before a request is issued. Thereafter, the
Disco device driver can talk to the device directly. Especially in the
case of devices accessed by a single virtual machine, the I/O resource
doesn't get virtualized at all, except for DMA requests. Disco's internal
device driver interface much resembles that of other operating systems, to
simplify the use of ready-made device drivers within it. Disco, in fact,
internally uses IRIX device drivers.
Real, modifiable disks are not virtualized. Onle one virtual machine may
mount a disk. Others can share data on those disks by using NFS, through
the virtual machine that mounts the disk.
For non-persistently modifiable disks, the concept of a
copy-on-write disk is used by Disco. This is for disks with code or
read-only data, where modifications don't need to be kept after a virtual
machine reboots. Those are read-shared under the virtual machines, so that
disk accesses to their pages are almost instant, one the disk page is in
memory. In other words, a secondary buffer cache exists under all virtual
machines.
A network interfaces are virtualized and given their own data-link
addresses on different virtual machines. When a distributed file system
protocol like NFS is used, pages are shared instead of copied whenever
possible.
Most commodity Operating Systems have some sort of base hardware
abstraction layer, to simplify portability. Making minor changes on that
layer, makes virtualization faster and easier. For instance, an OS can be
made to use loads/stores to a specific address instead of certain
privileged instructions that only read or change the contents of a
privileged register.
It is extremely easy to use a specialized, thin operating systems that can
scale up to the entire multiprocessor without much work. Such is the case
for special operating systems supporting heavy scientific
applications. Commodity operating systems can run alongside unburdened
scientific applications, that will take up all available computing
resources when they find them unused.
2.44 The LOCUS Distributed Operating System (Bruce Walker, Gerald
Popek, Robert English, Charles Kline, Greg Thiel)
[119] LOCUS was a distributed operating system running on
heterogeneous machines. It had a distributed, replicated file system,
supported nested transactions, provided location-transparent naming and so
on and so forth.
Replication in a file system is great since it enhances availability and
performance. However, it can be hellish for maintaining concurrency
control.
There are multiple physical devices per filesystem (since its
replicated). Normally, physical devices are incomplete (i.e., they don't
contain the entire logical file system). Version numbers are used to
maintain concurrency. Access is transparent, regardless of the physical
location of a file (except for differences in performance).
The synchronization site (CSS) (which is the synchronization manager for a
file system) is assigned for all files within a filesystem. Updates are
possible even when not all copies are accessible (i.e., when the network
is partitioned). However, upon reintegration of the network partitions, a
reconciliation mechanism is applied to bring all copies of the file in
synch, especially if all disconnected copies had been updated in parallel.
The CSS is maintained in the mount table, which is globally
replicated. Subsequent accesses to a file (after the CSS has been
consulted) don't have to involve the manager.
Directory path traversals are done a component at a time, but shipping
multiple components to a remote storage server for a directory was
considered.
File operations are atomic. Commit and abort are supported. Old data
versions are kept through shadow paging. Update propagation is also done
in an atomic way, in case contact is lost halfway through the update.
File creations and deletions are handled just like file
modifications. Storage Servers (SS) for new files are chosen among those
of the parent directory.
For architecture-specific file location (different executables for
different architectures)), a hidden directory is created with the name of
the ambiguous file. Inside this directory, files named after different
architectures are contained (e.g., /bin/ls/i386 is the file that's going
to be executed when I execute /bin/ls on an i386 machine. On a SPARC
machine, /bin/ls/SPARC is going to be executed instead).
Processes can be forked locally or remotely in a transparent way. A
combined fork and exec has been provided, to avoid futile address space
copying (especially over a network link). Shared resource semantics (open
files, pipes) is handled through a token technique, whereby access is only
allowed when the token is held by the node.
Within a partition, shared resources are strictly synchronized. Upon
reintegration, conflicts are resolved automatically for understood
resource types (say mailboxes), or a higher arviter is
required. Partitions aren't just disconnections through router failure;
they can be due to maintenance, negligence and so on.
Primary copy, majority consensus and weighted voting can allow
updates on only one of the partitions.
Both bundled updates and unrelated updates are handled.
Reconfiguration involves:
- Partition detection
- Find maximum partitions visible from each of
their members.
- Merging
- Attempt to merge the current partition with other
partitions that might have reconnected since the last detection
phase. Also reset CSSes and mount tables.
- Cleanup
- After a change in the partition membership, reset locks and
such to reflect current conditions.
The three reconfiguration protocols are combined, preventing deadlocks by
using protocol ordering (i.e., being strict on what runs when) and node
ordering.
2.45 VAXclusters: A Closely-Coupled Distributed System (Nancy
P. Kronenberg, Henry M. Levy, William D. Strecker)
[65] An intermediate construct, between tightly-coupled
multiprocessors and loosely-coupled distributed systems. It's like a
NetworkOfWorkstations approach, only for VAX machines.
The interconnect ports provide both a guaranteed, reliable, in order
message service and a UDP-like, unreliable service. They also allow direct
transfers of block data from virtual memory to virtual memory without the
intervention of the operating system. Data is sent through the
interconnect ports using 7 queues (4 outgoing data queues in 4 different
priorities, 1 response queue for incoming data, and 2 pool queues with
free messages and datagrams). The host program need only place the
information it needs sent in those queues and the interconnect hardware
will read the queue elements in the right priority and send them back,
without bothering the CPU. Incoming data is placed in the queue and an
interrupt handler can deal with all incoming packets in the queue, before
returning, significantly reducing the delay through interrupts.
Disk systems (a disk with an interconnect component) can also participate
in the network, providing storage facilities for all machines in the
cluster. Access to those disks is also provided through the
message-oriented interface described above.
Device Management is greatly simplified:
- single interface to all devices
- better sharing
- better usage
On each node, connection managers deal with locating resources, detecting
recoverable failures, integrating new cluster members and so on. A quorum
scheme is used to determine cluster membership. When operational members
become fewer than the quorum value, then the cluster suspends activity
until enough nodes have come back up. If a node fails and restarts before
its membership times out, it's allowed to rejoin. Otherwise, it's told to
reboot, before it can reenter the cluster.
Synchronization is handled by the distributed lock manager. This deals
with awarding, maintaining and releasing locks of different types (shared,
exclusive read-only, exclusive, ...) on objects of different types (from
an entire file system to specific records of a file). For each
hierarchical tree of objects, the master is the node that first requested
a lock on the root of the tree. It has to keep track of granted locks and
queues of waiters for incompatible locks. Lock masters are located through
a lock directory, which associates a master with a resource
name. Directories are also handled in a distributed manner. Given a
resource name, a hash function yields the owner of the directory for that
name (assuming a specific, well known number of members in the cluster).
During a cluster transition (e.g., addition of a new member, or escape of
an old member), operations halt temporarily. All lock managers deallocate
locks acquired on behalf of other systems. Then, each lock manager
reacquires the remote locks it was holding in other systems, thereby
redistributing masters and directories (since the membership number has
changed).
All lock manager operations are optimized when applied locally.
This system was unique in that software and hardware were being designed
together, with a specific common goal: the creation of a clustered system
of simpler, commodity-like machines. When the hardware is given, many more
compromises than listed here have to be made.
2.46 Hive: Faults Containment for Shared-Memory Multiprocessors
(Chapin, John and Rosenblum, Mendel and Devine, Scott and Lahiri,
Tirthankar and Teodosiu, Dan and Gupta, Anoop)
[23] It is an operating system for a shared-memory
multiprocessor. It strives to minimize the impact of failures of
individual processors to the operational state of the entire
multiprocessor. Main tools:
- There is an independent kernel (called cell) running on each
processor. Only the cell where a fault occurred crashes.
- Very few kernel resources are shared by processes running on
different processors. Scalability can therefore increase better as
processors are added.
This approach creates the following challenges:
- Faulting processors must be prevented from corrupting the rest.
- Resources must be shared, despite fault containment.
- The cellular set of kernels must present a single system interface
to the outside world.
Fault containment has three components:
- Protection from identifiably misguided processors. Pages can be
safeguarded from wild writes by firewalls.
- Recoverability from identifiably faulty modifications. Pages written
by faulting processors are preemptively discarded.
- Detection of misguided processors. At first, it's enabled by
heuristics, then confirmed by a consensus protocol.
A firewall is a feature of the FLASH architecture, whereby a processor can
associate a 64-bit vector which each memory page in its local memory. Each
bit in this vector represents a processor in the system (if there are more
processors than bits, some sort of aggregation is done). A write attempt
by a processor not allowed to write a remote page results in a bus error.
Memory sharing can occur in two ways:
- 1.
- Active sharing of a page used by processes on multiple cells
- 2.
- Loans of pages to cells with a shortage by others.
Resource allocation is handled by Wax, a user-level process running
on all cells. Cells sanity-check input received from Wax; therefore,
faulty operation of Wax can only hurt performance, not correctness. When a
cell is rebooted because of failure, Wax is terminated and restarted
across all remaining cells, once the system is stable again. This
simplifies its structure.
Faults can appear in both software and hardware. In hardware, the
interconnect can malfunction because of a faulting processor, similarly, a
faulting processor can cause the memory lines it has access to to
misbehave. Similarly in software, the errant kernel is the component
responsible for fault containment. Therefore, when the kernel is
misbehaving, wild writes cannot be avoided, unless there's hardware
support (for example in the coherence controller), or a trusted,
lower-level software component (as is the case in a microkernel
architecture).
Three types of fault ``contamination'' have been identified and dealt
with:
- Message exchanges
- All received results from RPC are sanity
checked. Requests are assigned timeouts to avoid waiting indefinitely.
- Remote reads
- Cells are careful not to be crashed while reading
another cell's internal data structures (through bus errors), dangling
pointers (by checking alignment and allocator tags), or unprotected data
modifications (by copying structures locally before checking them).
- Remote writes
- The FLASH firewall mechanism prevents cells from
writing other cells' internal data structures. All user pages used only by
local processes are protected from remote modification. Otherwise, all
pages that could have been touched by a remote cell pronounced
faulty are discarded.
All cells monitor all other cells for signs of insanity using heuristics
(for example, timed-out RPC calls, bus errors trying to access remote
memory, remote clock monitoring, failed consistency checks on remote,
internal pointers). Once an indication has been registered, normal
operation of the system halts temporarily, and all cells engage in a
distributed consensus protocol, to decide whether the suspect cell is in
fact faulty. If the consensus is affirmative, then the faulty cell is
rebooted. This second phase guards against insane cells pronouncing every
other cell faulty and automatically rebooting them. Furthermore, cells
accusing others of insanity, if voted down twice in a row for the same
accusation, are considered corrupt.
Recovery is performed in two phases. In the first phase, TLBs are flushed,
remote mappings are removed from process address spaces. After a first
barrier has been crossed by all, the second phase cleans up virtual
memory, by resetting all firewall write permissions and discarding pages
that were writeable by the faulting node. After the second barrier is
crossed, cells can resume operations.
2.47 Extensibility, Safety and Performance in the SPIN Operating
System (Bershad, Brian N. and Savage, Stefan and Pardyak, Przemysaw and
Sirer, Emin Gün and Fiuczynski, Marc E. and Becker, David and Chamgers,
Craig and Eggers, Susan)
[15] Extend the operating system services, to make the
system correspond better to the requirements of specific applications. In
this way, different clients can get independent specializations.
Provide
- extensibility (through interfaces and fine-grained access)
- safety (by avoiding exposure to actions of others, and controlling
access at the same granularity as that of the extensions)
- performance (by minimizing the overhead between the extensions and
the system)
All that is given through the following techniques:
- co-location
- Put the code where it will be executed (in the kernel).
- enforced modularity
- Enforce it through the type-safety of the
associated language.
- logical protected name spaces
- Don't export to the extension what it
doesn't need to play with.
- dynamic call binding/event handling
- Hook extensions on top of
events inside the system.
Comparison to other approaches:
- Separation of mechanism from policy can be very complex for
arbitrary systems.
- Microkernels export everything and let applications implement the
services. The high communication overhead they induce leads designer to
coarser-grain systems.
- Little languages try to limit how they can be abused by limiting
their expressibility. However, that makes them less useful.
- Software fault isolation takes a brute force approach, since
everything is checked at run-time. It doesn't contain or deal with the
concept of an interface, i.e., a group of related functionalities.
Protection in SPIN is supported through capabilities and protection
domains.
Capabilities are unforgeable language-level pointers. They're supported
and protected by the language (Modula 3) and impose no run-time
overhead. The kernel externalizes them through indices into a kernel-level
capability pointer table (much like file descriptors in Unix).
Protection domains are interface name spaces. They're created from ``safe''
object files (i.e., object files signed by a trusted Modula-3 compiler, or
asserted to be trusted by an administrator). Such namespaces can be
combined, resolved and so on.
The extension model is mainly based on events and event handlers. An event
is any function call within the kernel and handlers are alternate or
replacement implementations for these function calls. For example, a page
fault trap is an event and a piece of code that handles such a trap is a
handler for it. Handlers are linked to events by a central dispatcher. An
event handler can be a procedure or a chain of procedures. Handlers can be
applied selectively, if an associated predicate succeeds (these predicates
are called guards).
The Dispatcher is a big bottleneck, especially when multiple guards need
to be evaluated. Event handlers are, in general, very deeply trusted once
their credentials have been validated. In other words, a trusted misbehaving
extension (for example, a buggy extension), can wreak havoc in the system
in many ways (an example is holding down a lock on a resource, causing
starvation on threads of control needing that resource).
2.48 Automatic Inference of Models for Statistical Code Compression
(Christopher W. Fraser)
[42] The idea behind the whole thing is being able to provide
compression algorithms with better statistical models of code, so that
they can improve compression efficiency.
This is important, since code compression is becoming very attractive,
both to reduce transmission speed of code over a network, and also to
reduce access times from secondary storage and footprint.
The statistical model of a chunk of code is useful, because it determines
how output symbols are assigned to input symbols: frequently occurring
input symbols are assigned shorter output symbols, since the overall goal
is to minimize the length of the output symbol stream.
The objective of a modeller is to output a bunch of contexts, which
are identifiable states in the linear scanning of a code stream where
symbol probabilities are relatively stable, and their associated
probability distributions. To determine such contexts and
probability distributions, a modeller checks a specific set of
predictors, such as stack lengh, instruction under the cursor,
etc., to output something like the following decision tree, which for each
decision through the predictor set, yields a probability distribution:
if instruction=comparison
then use distribution_that_favors_branches
else if stackHeight=1
then use distribution_that_precludes_binary_operators
else use other_distribution
These decision trees are created by a simple algorithm that attempts to
minimize the total entropy of the code stream. Implementations of the
algorithm are still slow for on-the-fly model inference, but they are very
useful for long-term compression (such as that used before code is stored
on stable storage).
Commonly used predictors are:
- The last few (10-20) tokens seen. This catches cases like
comparisons followed by branches, or additions of 1.
- Computed predictors, like the stack height or the data types of the
last few operations.
- Projected predictors, which extract equivalence classes from
specific instances (for example, projecting all different comparison
operators like EQ or GT onto a single, REL operator).
2.49 A Hardware Architecture for Implementing Protection Rings (Schroeder, Michael D. and Saltzer, Jerome H.)
[104] Hardware considerations for a ring protection mechanism.
Criteria to judge access control mechanisms:
- Functional capability (or functionality)
- A mechanism must to ``meet
interesting protection needs'', which can be accomplished by the
primitives provided, and do so ``in a natural way'', which qualifies the
user interface.
- Economy (or performance)
- The cost of specification and enforcement
should be low enough not to be a concern in the selection of a
mechanism. The actual cost should be proportional to the functionality
actually used, not to the functionality available.
- Simplicity
- Lack of simplicity often means lack of security (since
complex systems are tough to understand and test).
- Generality
- The internal structure of components should be
independent of external access controls.
The above criteria are usually combined by keeping the latter three
constrained within reasonable ranges, and trying to provide as much of the
former.
In this work, the classic Multics segmentation architecture is assumed,
ignoring paging.
Protection rings were motivated by the need to change a process'
privileges, as it is executing different code. Note that in Multics, a
process is loosely equivalent to a user shell. Different segments are
equivalent to programs/processes in Unix.
A protection ring is a generalization of protection domains. Instead of
only having user and supervisor domains, there exist now r domains
totally ordered in terms of the privileges they convey (0 being the most
powerful). Each process executes in a single ring at any time. Each
segment defines a privilege bracket for every possible right (read,
write, execute) when the right is enabled by the associated
flag. A process has the right if and only if its ring lies within the
associated bracket for the segment accessed.
A process can increase its ring freely, since ring increase means
monotonic reduction of privileges. Ring decrease, however, is heavily
controlled, since it imparts additional privileges. Special locations
within a segment are defined, called gates. A process can raise its
ring number to that necessary to execute a particular segment only when it
jumps directly into one of those gates. The ring decrease is only allowed
when jumping into the gates from a particular range of rings (called the
gate extension). The gate extension effectively describes the rings
from which a downward jump into a privileged segment is allowed. For rings
above the gate extension, a downward jump is disallowed. Gates and gate
extensions are stored in the descriptor of a segment and are originally
read from the access control list associated with a segment on storage.
Execute and write rights always overlap only in a single ring, if they
are both allowed on a segment. This makes sure that only the ring with the
highest execute privileges is allowed to write a segment.
For an example, consider a segment A with a 0-3 write bracket, a 3-4execute bracket and a +2 gate extension. A process in ring 5 may jump
into one of A's gates, and lower its ring to 4, since ring 5 is within 2
of ring 4 (the top of the execute bracket of A). However, a process in
ring 7 may not jump into one of A's gates (and therefore, may not lower
its ring through A), because ring 7 is not within 2 or ring 4 (the top
of the execute bracket of A).
Calls and returns can cause problems when the protection domain changes
between caller and callee. Caller-callee environments must be independent
(i.e., the environment of lower-ring segments should not be accessible by
higher-ring segments). For an example, consider caller-callee stacks
should be independent: Stack records written at ring n should not be
accessible at ring m>n. Otherwise, consider segment A executing at nand calling segment B executing at m. If B has access to A's stack
records, it can alter them, thereby causing B to return to code it
didn't intend to execute. This is solved by having different stack
segments for each ring, making sure that the stack segment for ring n is
not accessible at any ring m>n.
In the case where the call lowers the ring number, the callee must ensure
it doesn't rely on the caller for its correct operation (since the caller
is, in fact, less trusted). The caller must make sure it doesn't allow the
callee to circumvent trust boundaries:
- The callee must be able to locate a stack area without relying on
any information received by the caller. This is accomplished by reserving
specific segment numbers for related ring stack segments (e.g., ring nhas its stack in segment f(n)). A special word in each segment (reserved
by convention) stores the current stack pointer offset for that
ring.
- The callee shouldn't allow the caller to use as arguments for a call
data the caller couldn't access in the first place (for example, a caller
at m shouldn't trick the callee to use arguments accessible at l>m,
even if the callee executes at n>l>m.). Therefore, the callee must
validate arguments against the caller's ring number, to make sure they are
legitimate arguments given the caller. The hardware allows the association
of a higher ring number with specific instructions. Therefore, if the
callee knows the caller's ring number, it can access the arguements using
this more restricted ring number.
- For reasons described in the previous problem, the callee must know
the caller's ring. This is also important when returning from the call,
since the ring should be restored to no lower than what the caller
had. This is solved by causing the processor to put the ring from which is
switched in a process-accessible register.
Calls at the same protection domain work exactly as described
above. However, upward calls also have problems.
- It's possible that the caller's arguments are inaccessible by the
callee. Some possible HW solutions are described but are all unpleasant
and clumsy.
- The return jump must proceed through a gate (since it advances from
a higher to a lower ring). Such gates should be only used for the return
jump (i.e., not for other jumps which could be performed further down the
calling stack). This means that gates should be managed in a stack-like
fashion. This is beyond what HW could do.
To fix the problems above (which seem to be difficult to fix correctly in
hardware), upward calls trap into the OS, which sets the environment
accordingly.
A suggested ring organization for Multics would be:
- Hard-core supervisor routines (access control, I/O, virtual memory,
scheduling) on ring 0.
- Less critical supervisor routines (accouting, ...) on ring 1.
- Procedures with access to supervisor routines (through defined
gates) on rings 2-5. At this level, protected user-level subsystems could
live on rings 2 and 3. All normal user processes would run on
4. Therefore, common shared libraries on 2 and 3 could be protected,
without the need to be included in the supervisor. Ring 5 could be used
for debugging (i.e., self protection).
- Procedures without access to supervisor routines on rings 6 and
7. Such would be controlled-environment procedures, being checked by
user-level procedures running on 4. For example, a generating procedure on
6 could be tested by an evaluator running on 4.
Protection rings don't deal with ``mutually suspicious programs'', running
with the same amount of privileges over a trusted arbiter.
2.50 TOPS: An Architecture for Telephony Over Packet Networks
(N. Anerousis and R. Gopalakrishnan and C.R. Kalmanek and A.E. Kaplan and
W.T. Marshall and P.P. Mishra and P.Z. Onufryk and K.K. Ramakrishnan and
C.J. Sreenan)
[5] Integration of heterogeneous networks at the application
level.
Target application is telephony (and telephony-related services, like
voice mail). The main contribution is an architecture for connecting
telphony networks with the Internet, and the associated protocols for
using packet-based transports to carry logical channels.
It's main components are:
- A Directory Service
- Its main goal is to associate a ``distinguished
name'' (a unique ID for a person) with a set of ``call appearances''
(application-specific profiles, including addressing info, terminal
capabilities, authentication keys etc.) and a set of ``query handling
profiles'' (a set of matching rules, determining which call appearances
will be returned to a particular caller). Each person has a ``home
directory'', which stores an uncacheable authoritative version of his
information. The home directory is located using an inter-server protocol.
- A Terminal Tracking Service
- Its main goal is to be the ``Home
Agent'' in IP-based or other networks. It pretty much tracks terminals
(what we call hosts in CS-land) when they change network
addresses. There's no concept of a foreign network, though. When a
terminal moves into the jurisdiction of another TTS, the directory entry
is changed to reflect the move and the old TTS becomes yesterday's news
(except for forwarding retarded packets).
- Gateways Galore
- To bridge the gap between packet networks and the
PSTN.
- An Application Layer Signaling protocol
- This deals with
multiplexing a single communications pipe among multiple data flows. Many
logical channels can live on top of a single transport connection and ALS
is responsible for helping that happen. It also deals with call
establishment and tear-down.
- An abstraction protocol for Logical Channels
- Here the
telecommunications world discovers the concept of multiplexing. The whole
idea of having independent flows of data (or control) over a single
transport-level connection is discussed.
- A set of conferencing mechanisms
- A very important aspect of any
conferencing mechanism is how it deals with echo cancellation. This echo
is caused by the fact that output at one of the participating stations is
``overheard'' by the microphone, reinserting it into the conference. The
net effect is that audio tends to echo multiple times in the conference,
until it eventually dies out. TOPS supports both centralized mixing (which
means, there's can either be a central echo server that mixes individual
signals and redistributes them, making sure the appropriate signal has been
cancelled for each recipient, or the cancellation occurs at each end host).
2.51 Adapting to Network and Client Variability via On-Demand
Dynamic Distillation (Armando Fox,and Steve Gribble and Eric A. Brewer and
Elan Amir)
[41] Basic motivation: networked devices are very diverse in
capabilities. How can the same content be delivered and used at all these
different devices, without being unduly duplicated or delayed?
Axes of variability:
- Screen size
- Bandwidth
- color depth
- processing power
- available content encoding capability
- (not mentioned) power consumption
General idea: perform lossy on-demand content type conversion, to minimize
network latency and bandwidth requirements. This goal can be achieved
through the following three techniques:
- 1.
- Type- and semantics-specific lossy compression (distillation
and refinement). The specialization of the compression to fit the
semantic content under consideration can produce better results than
generic compressors can.
The semantic type (text, image, video) and the encoding (postscript, mpeg,
...) are logically independent. It is the content that's distilled, to
reduce detail or quality (e.g., image resolution or color depth), but some
operations are easier in some encodings than others. Refinement, on the
other hand, allows the user to decide whether the full-blown,
``expensive'' version of some content should be downloaded, by looking at
the ``cheap'', distilled version. Refinement amounts to an informed
zoom-in operation, in terms of quality.
- 2.
- On-the-fly compression, though it can add some latency due to the
computation involved, can eventually reduce latency, since compression
results in less data to transfer.
Besides, on-the-fly compression can also be customized to the particular
needs of the client that initiated it (as opposed to using pre-distilled
stored versions of the original content, and pigeonholing clients to
available versions).
- 3.
- Removal of compression/adaptation mechanisms from the clients and
servers results in happier servers (faster for what they perceive as the
common case, since they don't have to waste cycles on adaptation, or space
for multiple versions of content), happier clients (less
memory/storage/power wastage), and richer proxy business owners. Besides,
legacy servers can still serve clients with unique limitations.
Current techniques for dealing with client variability include providing
multiple versions of the content (which means a bigger administrative mess
and still leaves some requirements out), or just supporting one side of
the fight (i.e., either the low end clients or the extra-heavy-duty
high-end clients). Even when coarse-grained refinement is allowed (as is
the case with web browsers supporting progressive image encoding
techniques), it's done in a way that ignores semantics, or value of
different parts of the conent, thereby treating bundled content
indistinguishably.
The basic components of the proposed architecture are as follows:
- Proxy
- It lives on the boundary between the slow and the fast
network (or the two networks displaying heterogeneous characteristics). It
figures out what needs to be done to turn the content into what the client
can experience, and calls the appropriate distillers.
- Distillers
- These provide the actual smarts of converting contents
of different semantic type to fit the needs of clients.
- Network Connection Monitor
- This keeps track of changes in the
condition of the connections between a proxy and its clients. When the
link status (effective quality) changes, the proxy adapts its conversions
to fit the situation optimally. It can also be told what the conditions
are by the user.
- Client-side support
- Proxy-aware applications are linked with a
special library, communicating with the proxy through a standard
API. Proxy-unaware applications are using a ``client-side agent'', which
fakes the API of a server to them, and then talks to the proxy.
2.52 The design and implementation of an intentional naming system
(William Adjie-Winoto, Elliot Schwartz, Hari Balakrishnan and Jeremy Lilley)
[1] INS is a resource discovery system for mobile networks,
based on attribute-value pair ``names''. Names describe what is
sought, not where the sought object lives. Message routing and name
resolution are bound together (the authors call this ``late binding''), so
that physical name mappings can change even during a long-lived
session. However, reliable delivery cannot be guaranteed with late
binding.
The expected mobility can come in different flavors:
- the sought service changes network address,
- the sought service changes network (i.e., from ethernet it moves
onto a wireless network),
- the characteristics of the sought service change (i.e., its
performance goes down or the network path to it becomes congested).
Example abstract names one can resolve in this scheme are: ``the closest
geographically, least loaded printer'', ``the least loaded fileserver with
the best network performance to where I am'', ``all mobile cameras in
section A of this building''.
Names belong to an attribute hierarchy. The nodes of the hierarchy are not
attributes; they are attribute-value pairs. This allows the children of a
node to change structure, depending on the value of the parent. A good
example from the paper is that ``country=us'' has a child ``state=CA'',
but ``country=canada'' has a child ``province=BC''. If we, instead, had
hierarchies of attributes and values, under country we'd have to deal with
both provinces and states.
Intentional Name Resolvers are both name resolvers and message
routers (since, in INS, messages piggyback data with the intentional name
of their destination). Services attach themselves on an INR, which
advertizes the attribute-value characteristics of its attached services to
its neighboring INRs.
Delivery to names can be one of the following:
- intentional anycast, or single-end picked among those
satisfying the intention of the name and optimized for an
application-controlled cost function, or
- intentional multicast, i.e., similar to multicast, where
group membership is determined by whether nodes satisfy the intention of a
name.
- early binding, i.e., single-step intentional resolution,
where the local name resolvers just returns the network addresses of those
servers it thinks best fit the intention.
The first two options belong to the ``late binding'' technique, where name
resolution and forwarding are done by the naming infrastructure. The third
option separates forwarding from naming.
For example, the name ``color printer'' would resolve to the closest,
fastest, highest-resolution color printer to where I am (if my cost
function is proximity, speed, resolution) in ``intentional anycast''; in
``intentional multicast'' the name would resolve to all color printers I
can reach. In early binding, it would just resolve to the network
addresses (IP addresses) of the color printers I know are out there, along
with their metrics, as I have them in my cache.
INRs organize themselves into a (not necessarily minimum) spanning tree,
using average delay (round-trip time) as the cost metric. Every new INR in
the INR cloud pings all others to figure out which currently active INR is
the closest one (using the delay metric). It picks that one as its next
hop neighbor. The tree is not minimum and it's not robust (it has many
single points of failure).
Periodic system-wide updates take the form of flooding. A new
name-specifier is made known, along with its associated IP address, port
number and transport type, a routing metric, the next hop INR along with
its delay metric and a unique identifier of the announcer.
The list of currently running INRs is maintained and provided by a central
Domain Space Resolver.
Clients can either request name resolution (along with forwarding, in the
case of late binding), or discovery. Clients themselves also have
intentional names (so that services can send them their results).
Services pick the metrics on which they wish to receive routing (for
instance, their average load, or their print resolution). They also set an
announcer ID for themselves (to differentiate them from other similar
services running on the same node). The ID is a concatenation of the IP
address with the startup time of the server process.
The main design goals addressed are:
- Expressiveness
- Responsiveness (i.e., quick adaptation to topology or quality
changes)
- Robustness
- Easy configuration (i.e., least manual effort)
Performance is significantly hurt by the CPU-intensive name resolution and
update processes. To alleviate the problem, partitioning services into
different virtual spaces has been proposed and tried.
In p. 188, fourth paragraph, why is forwarding the message to the ``best''
end node so much better and dynamic than early binding? Is this to save
against changes effected between the time of the resolution and the actual
use of the return network addresses?
In p. 189, figure 1, the service announcing an intentional name is in the
middle right of the figure, not the bottom right.
In p. 190, last paragraph. Why do we need the routing tables? We already
have routing tables at the IP level. Why do we route through INRs? Perhaps
to catch as yet unsettled updates?
There's no information on how a client finds and/or picks an INR.
It's not clear how v-spaces remain balanced.
The performance evaluation is rather superficial. Arbitrary distributions
are assumed for the growth of name trees and the behavior of virtual
spaces.
It is not clear why late binding is useful. If the first-hop INR is
rapidly updated, which is what the architecture strives to accomplish,
then why should the system go through the INR network to deliver the data?
2.53 Names should mean What, not Where (James W. O'Toole and David
K. Gifford
[84] A short, fairly forward-looking, thesis paper on using
content-based naming. The examples are not exactly obvious. Better
examples exist now of why content-based (or
intention-based[1]) naming is rapidly becoming
preferable. Mobility is definitely one very good example domain.
It's interesting to read pre-web literature. And this is merely 7 years
old.
2.54 A Model, Analysis, and Protocol Framework for Soft State-based
Communication (Suchitra Raman and Steven McCanne)
[97] A very dense, very impressive paper (received the best
student paper award in SigComm '99), modeling and analyzing soft-state
protocols.
Soft state was first coined by Clark in a SigComm '88
paper on the design philosophy of Internet Protocols, though not quite
fully defined. What makes state soft is that it can expire. As long as
there are refresh actions keeping it fresh, the state remains. When the
refreshes cease to appear, the state eventually goes away. This makes
recovery under failure much easier than having to deal with explicit,
``hard'' state that requires active restitution in the face of failure.
Soft state requires extra messages, since it relies on refresh.
The Internet is the perfect domain for soft state protocols, since it
contains endpoints with a wide range of failure rates, reliability
guarantees and performance characteristics. Soft state-based design fits
the Internet better, since it calibrates the design process to anticipate
conditions that occur quite often on the Internet.
This paper proposes a model for soft state protocols and defines a
consistency metric on it. It also suggests a soft state-based transport
protocol framework as a building block for the design of soft state
protocols.
The model assumed is one where the sender maintains a database of
attribute-value pairs
k,value(k) and periodically announces those on a
channel, from which receivers can extract pairs and insert them or update
them in their local databases. When a pair expires on the receiver, it
gets removed. Additionally, pairs can be removed from the sender, which
causes the sender to stop refreshing them.
The consistency metric c(k,t) for an item k at time t between sender
S and receiver R is defined as
![$c(k,t)=Pr.[S.val(k)=R.val(k)], 0\leq
c(k,t)\leq 1$](img27.gif) ,
where P.val(k) is P's value of k. Given this definition,
instantaneous system consistency can be defined as the average
consistency over all items in the database at time t and, similarly,
average system consistency can be defined as the time average of
the instantaneous system consistency over a long time period. A system is
eventually consistent when the instantaneous system consistency
approaches 1 a long time after the last item has been inserted in the
sender's database.
,
where P.val(k) is P's value of k. Given this definition,
instantaneous system consistency can be defined as the average
consistency over all items in the database at time t and, similarly,
average system consistency can be defined as the time average of
the instantaneous system consistency over a long time period. A system is
eventually consistent when the instantaneous system consistency
approaches 1 a long time after the last item has been inserted in the
sender's database.
Periodic updates are good enough to foster eventual consistency over a
lossy medium, but they can be expensive (redundancy) and can cause undue
propagation delays.
Unfortunately, most of this section went right over my head. However, the
gist of it describes a simple refresh scheduler (FIFO) and analyzes its
performance and bandwidth wastage. The simple FIFO scheduler maintains
system consistency between 85 and 95% for loss rates in the 1-10% range
(with a 15% probability that value-attribute pairs will be removed from
the sender). For loss rates as high as 50%, and pair removal probability
of 10%, bandwidth waste is calculated around 90%.
A better way to manage refresh transmissions is to use the tried and true
technique of ageing data. Retransmissions (refreshes) are considered less
important than new transmissions (of new attribute-value attributes or
updated ones). Therefore, there now exist two transmission queues at the
scheduler, a ``cold'' one (refreshes) and a ``hot'' one (new). Through
simulation, the authors have shown that when the bandwidth used by the hot
queue is slightly higher than the rate of update at the sender, system
consistency is maximized. Furthermore, update latency decreases as the
bandwidth used by the cold queue is increased.
To make retransmissions more effective, a receiver feedback mechanism is
added in the scheme, where detected losses by the receiver create a
negative acknowledgement. When an item is declared missed by the receiver,
it is moved into the hot queue again by the sender. In other words, the
hot queue contains not only new transmissions but also requested
retransmissions; the cold queue contains only spontaneous refreshes.
When the bandwidth used by feedback traffic (NACKs) is between 20 and 60%
of the total bandwidth, consistency reaches almost perfect levels.
This is just a nice, packaged form of the theory derived in the first part
of this paper. It allows applications to specify what levels of
consistency they expect from the tranport layer. Then SSTP arranges the
bandwidths used by hold and cold queues to achieve that consistency. It
also relies on receiver reports to be informed on the observed loss
rate. Finally, it requires some separate module to tell it what the
available bandwidth is.
SSTP provides upcalls to the application, to allow it to change its
behavior when the consistency ``guarantees'' are not maintained. Such is a
case when the application feeds data into SSTP faster than the bandwidth
it has allocated for the hot queue.
To deal with large data spaces, SSTP allows applications to put their
``soft'' data in hierarchical name spaces. Transmission and update of such
name spaces is done in a recursive descent-based manner. In this way, some
receivers might decide to skip parts of the name tree (and, therefore, not
request those parts).
Despite the importance of the contained work, this is a really sloppy
paper, apparently not very carefully proofread. Especially the analysis
sections (3-5) lack basic continuity, like explaining what some of the
symbols used signify and the like. The graphs are minimally captioned and
not adequately explored in the text. There's a figure that's never even
mentioned in the text. This is a real shame, since this is an otherwise
extremely cool paper. Pity.
2.55 RFC 1546: Host Anycasting Service (C. Partridge and T. Mendez and W. Milliken)
[87] This deals with the concept of picking one Internet host
among many of the same class, based on some application-specific
characteristics.
Should this be implemented at the IP level, there are several important
and difficult issues to deal with:
- If we're using an anycast address to access a ``virtual''
host, how do we make sure that all packets in the same flow are delivered
to the same member of the virtual host group?
- How are anycasting addresses assigned? Carving out a class of
addresses out of the severely crowded IP address bit space would impose
additional limits on address distribution, making it easier, though, to
route anycasting packets. Ad-hoc designation of addresses as anycasting
addresses makes a more efficient use of the IP address space, but makes
routing extremely difficult (since there are no clear ways to mark an
address as an anycast address).
- State-ful protocols, like TCP, cannot rely on anycast for continued
communication with another TCP stack. The best way to deal with this is to
replace the anycast address with a unicast address (the address of the
first SYN-ACK received) and proceed to communicate with that host using
unicast.
- Anycast packet routing on local networks (where a router cannot be
assumed to exist) have to rely either on proxy ARP (i.e., an anycast
participant has to respond to an ARP request for the anycast address), or
on link-level multicast addresses. The ARP approach will cause more ARP
response transmissions (since the caches must prediodically be refreshed),
whereas the multicast approach will cause all anycast packets to be
received by more than one hosts.
This is an early attempt at ``what''-not-``where'' addressing and
naming. Obviously, the criteria selecting members from anycasting groups
can only be those understood by routers (hop counts or link bandwidths at
the most). For more advanced criteria, application-level smarts will be
required. Furthermore, the hackiness of it all is just mindboggling.
Bottomline is, too much overloading (in the OO sense) can be bad for your
designing health.
2.56 A Survey of Active Network Research (David L. Tennenhouse,
Jonathan M. Smith, W. David Sincoskie, David J. Wetherall, Gary
J. Minden)
[113] A high-level presentation of active network
research.
Basic idea of active networks: network switches perform customized
computation on the messages flowing through them.
There are two ways in which active networks have been visualized:
- The Programmable Switch Approach. Data passing and switch
programming are discrete actions. By unbundling the programming and
forwarding functionalities, we can make the programming part (which is the
inherently scary, insecure one) as complex and anal as desired. For
instance, complex checks can be imposed on the shipped code to make sure
that it doesn't do bad things (anything from software fault isolation to
instrumentation, as in vino).
- The capsule approach. Data packets are replaced by
data/processing capsules, much like in the case of postscript replacing a
text document.
Program encoding must, in general, support mobility (i.e., be
independent of platform and location), safety (i.e., provide ways
to restrict the accessible system resources), and efficiency (i.e.,
make sure that in most common cases performance is not horribly
penalized).
The kind of functionality available would cover packet manipulation,
access to switch environment (time, address, link status, etc.), packet
flow manipulation.
The program model must also defined a common resource model (routing
tables, link status, routing capabilities). Defining a secure resource
allocation mechanism is a hard problem.
Systems with use in this framework include Safe-Tcl, Java, Omniware and
Proof-carrying code.
- New protocol deployment could turn out to be instantaneous.
- User-aware network protection. Use exactly as much as you need. Not
entirely clear how you'd do that.
- Infrastructure safety. Unleashing arbitrary pieces of code in core
switches can be hazardous to the network's health.
Some additional issues/disadvantages not clearly mentioned are
- State tracking: Whether soft or congealed, state has to be
maintained all along a network path, which means more memory, operations
to retrieve it and so on. To make the state soft, packets have to have
redundant information to potentially regenerate expired state, or latency
might have to be added for on-demand state retrieval. In the case of hard
state, we have to deal with robustness, invalidations and the like.
2.57 Active Names: Flexible Location and Transport of Wide-Area
Resources (Amin Vahdat, Michael Dahlin, Thomas Anderson, Amit Aggarwal)
[117] Another take on the deployment of wide-area services.
The spin is that instead of plugging the code where the data are going to
pass through (which is what Active Networks do [113]), we
map the path name to a sequence of operators (i.e., we let the path be
calculated dynamically).
This is an overlay mechanism, in that IP-level routing is not supplanted.
Example applications would be replica selection in a replicated framework,
mobile distillation (where the distillers can move to minimize perceived
latency), or customizable client caches.
This is yet another approach to naming things using the ``what'', not the
``where'', otherwise called Intentional
Naming [1]. Intentional Naming bundles location and
transport in one nice package, which allows location to be swayed by
available transports or, conversely, transport be swayed by how we named
the endpoint. In contrast, ``Extensional Naming'' breaks up location and
transport. This might seem simpler (since it is conducive to modularized
solutions), but it implies some hard state: If a name resolves to a
transport address, this address must be continuously supported, though it
might have nothing to do with what is named (e.g., in mobile systems).
Active names pay the mobile code premium once per session, whereas active
networks pay it per packet. This allows active networks to change their
behavior per packet, which active names cannot.
Their main design goals are:
- Namespace customization and extensibility. The system must be
``complete'', in that it should be able to do anything (?).
- composability
- efficiency
- location-independent resolution
The scheme works like this:
- 1.
- Client C wants service S.
- 2.
- C builds an Active Name AN: [Name N:Namespace Program NS].
- 3.
- AN is shipped to the nearest resolver R.
- 4.
- R locates NS from the reference to it in AN.
- 5.
- R runs NS on N. It resolves part of N, which it uses to figure out
where (what namespace program NS') to send the remainder N' of N. The
computation it determines that has to be performed is formulated as an
After-Method AM and pushed down a stack in AN.
- 6.
- N' is shipped to another resolver, where NS' is going to be executed
to resolve it and so on, until a leaf is reached. Along with N' and NS',
the stack of after methods is also moved along.
- 7.
- When the entire name has been resolved, a chain of after methods has
been derived. After methods are bidirectional pipes, chained together into
one pipeline where the input data (S) is going to be directed. The output
of the pipeline will be delivered to the destination (customarily, C).
In , the location of NS may also be an active
name. Obviously, there needs to be a ground case in this recursion. Such
is the case for some primitive services (like HTTP or DNS).
Resolvers are pretty much compute servers with some necessary
functionality:
- They must be able to fetch names and namespace programs
- They must be able to execute programs safely in a controlled
environment (something like a sandbox virtual machine).
- They must be able to retain (cache) soft state about previous
resolutions.
- They must be able to communicate with next-hop resolvers.
- They must be able to respect authentication/authorization
restrictions imposed by namespaces.
The paper compares active naming to active networks or active services
before it has even talked about what exactly active naming is (they do
talk about it, but in too fluffy terms to actually be helpful). This can
be very annoying.
Unfortunately, according to the authors, there are many security issues
that still need to be resolved.
The described applications of the scheme are pretty convincing, especially
in the case of mobile distillation.
2.58 Designing a Global Name Service (Butler W. Lampson)
[67] A great quote from the paper:
"There are already enough names.
One must know when to stop.
Knowing when to stop averts trouble."
Tao Te Ching
Context: Name service for all computers and all people in the world. In
general, only very few pairs of principals will have any communication
exchanges at all. Assume the names change slowly, and the properties
associated with names also change slowly. The name service is also large,
long lived, highly available, invulnerable to local faults and tolerant of
mistrust. It all sounds a lot like a hierarchy.
From the client's standpoint, a hierarchical name tree is seen. Symbolic
links are supported. The top part of the tree consists of
directories. Each directory has a unique identifier (something like an
i-node in a Unix File System hierarchy). From each super-directory,
subdirectories can be reached through named arcs (file names in a Unix
File System hierarchy). So, nodes in the tree are independent of the names
through which they're reachable. From directory leaves, value trees
spawn. Value trees are also name trees where an arc is a name. Nodes
contain time stamps and a present/absent flag.
In the above scheme, we can name single values, sets of values, or
subtrees. Each directory has an access control function that maps
principals and name paths into rights (R, W, test). Each directory has an
authentication function from an encryption key to a principal. Some
mappings in those functions are maintained externally, since no Public Key
Infrastructure is assumed (i.e., by a courier).
At the administrative level, replication and subtree/server associations
are visible. Every tree directory arc, except for the directory identifier
it points to, also contains a list of servers on which that directory
identifier lives (any of them can be picked). Servers are also named in
the name tree.
Updates originate at one of the copies and later on propagated to the rest
of them. This happens during a sweep operation, which collects
updates from all copies of a directory and then spreads them through all
of them, resetting their last sweep timestamp. The entire set of servers
can't be reliably retrieved from the parent (after all, the parent might
be undergoing update as we check it). So all servers are connected in a
ring, through which a sweep proceeds to update all of
them. Disconnections, network partitions, failures lead to disruption of
the ring. Ring reformulations occur manually by an administrator, and they
mean the advent of a new epoch.
Administration operations under different subtrees are independent and
need not be coordinated. When, however, trees are merged together under a
new root (i.e., name services are combined into a new one), a scheme has
to map from the old well known root (for which an identifier, not a name,
was known) to a node in the new tree. This is done in a table of well
known nodes, which point from a directory identifier that used to be a
root, to a path in the current scheme. For every such reorganization, the
well known node table has to be translated to the new tree; this is done
infrequently enough, that the extra computational overhead is not an
issue.
Restructuring, that is moves of entire subtrees under another subtree, is
handled using symbolic links, so that paths leading to the old location of
a subtree have pointers to the new location of the same subtree.
To permit caching, each entry has an expiration time. No entry can change
before its expiration time has passed (except, perhaps, it can move to a
different subtree, as long as there's a symbolic link to its new
location). Therefore, clients can safely cache copies of past lookups,
until their expiration time.
Value updates must be:
- Total (we can't have them be undefined for a particular state of the
database)
- Commutative (their order shouldn't count, or concurrency is going to
be a pain)
- Idempotent (they should yield the same result, no matter how many
times they're applied, to cover replays and other nasty little habits of
distributed systems)
On this basis, updates are specified on timestamped paths (i.e., every
component of the path has a timestamp identifying the particular node the
client intended to follow). Earlier timestamps are superseded by later
timestamps.
Directory lookups reflect the state of a directory after all
updates prior to the sweep time of the directory, and some of the updates
after that sweep time.
Every server stores a pointer to a server that's closer to the root than
itself, unless the former server does store the root. Also, a server
cannot contain the only copy of the directory that leads to it from the
root. Otherwise, an infinite loop trying to locate that directory would
ensue.
Network partitions have to have user intervention to be dealt with. That
sounds kind of silly.
No mention of time skew. Times are assumed globally synchronized.
This pretty much describes how DNS works except for a few differences:
- Changes can be introduced to an entry, before it has globally
expired.
- Entries don't have expiration times (since there's no reliable,
global time), but time-to-live values.
- The root can never change, so instead of up pointers from servers,
there is a well known table of root servers.
- Lookups are more permissive, since timestamps don't have to be a
part of a query.
2.59 Decentralizing a Global Naming Service for Improved
Performance and Fault Tolerance (David R. Cheriton and Timothy P. Mann)
[26] What do you do when you want to actually use the name
service much much much more frequently than [67] allows?
Say, for global file name service. Assume the existence and full
deployment of multicast.
Three target classes of operations:
- Binding
- assigning a name to an object, removing a name from an
object
- Query
- look if there are any objects assigned a name, if such a name
exists
- Mapping
- deliver a message to the object named by a name
General idea is to split the name hierarchy into multiple levels with
different characteristics:
- global
- Countries, types/groups of institutions. Members of this
level are mutually distrustful. Enforcement of uniqueness is recommended
(i.e., French sites can't be assigned names that appear among German
sites). They change relatively slowly, so they can be heavily cached. They
are extremely necessary for lower-level lookups, so high availability has
to be ensured through replication. Performance is not that critical.
- administrational
- Specific institutions, organizations. Members of
this level might be mutually distrustful, but they respect the arbitration
authority of the parent organization. They should be able to operate even
when disconnected from the global context. More dynamic, localized
information is represented, so a better, faster, more complete way of
maintaining coherence is better advised here.
- managerial
- Specific objects inside organizations, servers,
handlers, managers. They only need to be available as long as the service
they name is also available. They aren't as conducive to caching, because
of rapid changes in their mappings.
At the managerial level, a name server is collocated with the object
manager of the objects it handles. Once it receives a named request, it
can immediately dispatch it to the right object. Similarly, when the
manager is down, so is the name server. Getting to the right name
server/manager from a client is the job of prefix caches, and
realizing a name doesn't belong to any managers at all (i.e., it's a non
existent name), is the job of higher-level name servers.
The prefix cache contains path prefixes (i.e., a number of path
components) which map to specific managers. For example, the mount point
of an entire file server would be a path prefix and the server itself
would be the specific manager. Even deeper prefixes can be accommodated,
since for each entry, a manager identifier and a manager-specific
directory identifier is returned. In the example above, for a subtree of
the mount point of a file server, the file server's ID and the i-node of
the subtree would be returned.
If the cache lookup is a near miss, i.e., it identifies a directory
which is not a local managerial directory, then a probe operation on that
directory is initiated. This just multicasts the request on all those
managers covering (i.e., having mappings within) the local administrative
directory. When one of them responds, the entry is put into the cache and
operations proceed normally. If the near miss points to a name outside the
local administration, then a liaison server is probed for the right
managerial directory identifier. There's never a cache miss, since
there's always a cache entry for the root global name servers. If that
entry becomes stale, the client may resort to probing all nearby managers
and liaison servers (through scoped multicast), trying to locate a new root
entry.
When a cache entry becomes stale, then the server it was obtained from is
asked to wake up and smell the coffee, which gives feedback to the server
that it's caching stale entries. Stale entry detection is done either
through timeouts (i.e., looking for a manager that's not there any more),
or through appropriate error codes (for example, a manager replying that
it's not managing the named object any more; for that to work, requests
from clients have to contain both the [managerID, directoryID] tuple and
the name they think maps to that).
The advantages here are:
- Even a near miss provides useful information
- Having short prefixes instead of entire names in the cache improves
the hit rate
- On-use cache consistency checking might be slightly slower, but
doesn't impose preventing cache consistency checks, which could be
wasteful.
Administrational directory servers store, for each of their subtrees, sets
of managers that cover the associated name space. Obviously, they are
authoritative only for those prefixes that do not exist (i.e., those with
a subtree name they don't have).
At the global level, designs presented for instance by [67]
are used. Liaison servers become the front end to global level name
servers, making it easier for clients to deal with fewer naming
protocols.
To improve caching performance, cache inheritance is used. Parent
processes bequeath their naming caches to their children.
For nearby objects, mapping only fails when the object manager itself
fails or is inaccessible. Otherwise, (i.e., for objects outside the local
administrative domain), mapping can also fail if all the administrative
directory servers for the target organization are down and the client does
not have their member managers cached.
Queries (i.e., binding checks and listings) are resilient against most
managerial failures (since the administrational servers can answer
them). Complete resilience can be guaranteed only if all clients are
caching all global information.
Security covers:
- 1.
- Which clients are authorized to request information from a server
- 2.
- Which clients are authorized to update information on a server
- 3.
- Which servers are authorized to provide specific
information
The reverse authentication problem in above is the most
difficult, since a client doesn't even know which manager it wishes to
hear from, only that it should be "the right manager" for the particular
query. This is customarily solved using a capability-like scheme of
certificates. A certificate authority issues time-limited certificates for
each server stating that "server X is authorized to answer query Y for
time T". A server returns such certificates along with its signed
answers. When a certificate expires, the server needs to get a new one
from the certificate authority.
It's mentioned that object managers may choose to switch directory
identifiers fairly often, and administrational managers may choose to
switch the identifiers of managers fairly often (say for load
balancing). This means that invalidation of cache entries can be a fairly
frequent occurrence, unlike what's implied in the discussion in 3.2.
2.60 Recommendation X.500: Data Networks and Open System
Communications - Directory
[56] The ITU-T take on the Directory service.
A basic objective is to provide ``user-friendly naming'', whereby named
objects have names suitable for citing by human users. This is not
all-restrictive, i.e., some names might also be ``unfriendly''.
The other basic objective, naturally, is to contain ``name-to-address
mappings'' for indexed objects which are dynamic. In other words, the
served mappings may change over time.
This is not a database service. Queries are assumed to be much more
frequent than updates. Rates of change are assumed to follow ``human
standards'' as opposed to ``computer standards''. In other words, a
mapping is assumed to change at rates no faster than those that a human
could accomplish.
Eventual consistency is what counts here. Cases where both old and new
versions of some information float transiently through the system are
acceptable.
Except for access rights issues, results of a query are independent of the
identity or location of the inquirer.
The data model is assumed to be structured as a tree (and the interfaces
take that under consideration). However, other structures are not
precluded from existing in the future.
The data model (as described in X.501, which is as yet not electronically
available), is hierarchical, based on value-attribute nodes. A node
normally follows a schema that defines its type
(class). Administratively, the party responsible for a node defines
its own class and nothing else. Of course, defining the class of a node
also defines the possible classes of the node's descendants.
Aliasing is allowed. An alias node may point at a node somewhere else in
the data hierarchy.
Nodes (i.e., entries in the directory), have distinguished, unambiguous
names which are derived from the path connecting them to the root of the
hierarchy.
Intermediate and leaf nodes in the entry tree are identical in structure
(i.e., there's no special leaf node type).
The directory provides support for querying and modifying it. It provides
responses to all types of requests. Responses are however specific to the
request type.
The Directory offers optional support for mutual authentication of the
user and the directory.
It is possible to qualify how a request is going to be handled:
- Controls exist for limiting resource usage, interaction modes and so
on.
- A request may be accompanied by security info (digital signatures,
for example).
- A request may be accompanied by a limiting filter that helps return
a better selection of results from a larger class of them.
Query requests include read, compare (for instance, for password
checking), list, search and abandon (which tells the directory a previous
request is no longer relevant or needed). Query requests may contain a
context, that can be used when multiple versions of values are kept for
some of the attributes of a sought entry. A good example of context is
``language''.
Modification requests include add (leaf), remove (leaf), modify entry
(which is an atomic operation) and move (which moves an entire subtree
into a new location). Contexts may also be included in the request.
Exceptional conditions include errors (for anything from security issues
to schema rule violations or service controls) and referrals (which allow
a directory access point to refer a user agent to another, more suitable
access point - perhaps because the latter is closer to the requested
data).
Requests are handled by directory service agents either recursively (in
which case, if they don't personally know the answer, they'll find it from
other agents and return it to the requester), or by referral (in which
case, they'll point the requester to a more likely place for the posed
request).
The Directory service supports redundancy, in the form of shadowing (as
defined in X.525) or caching (which is considered an implementation issue,
as yet unspecified).
The shadowing model assumes a single owner of specific data. Shadowing is
read-only. All modification requests are forwarded to the data
owner. Partial shadowing is also permitted (whereby, not all components
within a subtree are shadowed; a filter predicate is used to define which
parts of a subtree are to be shadowed).
Inconsistencies are tolerated. In the case of shadowing, inconsistencies
are always temporary (although no time constraints are specified). In the
case of caching, no declaration is made. The only stipulation mentioned
for shadowing inconsistencies is that they never occur internally to an
object, i.e., the fields of a single object all contain information from
the same version of that object, whereas a shadowed copy of that object in
a different directory agent might contain an (entire) previous version of
it.
Replication is not transparent to the user. The user knows if a request
was satisfied from a shadow copy of the authoritative data. The user is
also allowed to specify that a request should be satisfied by the master
directory server, for better accuracy, at the expense of performance.
Access to the Directory is allowed through the Directory Access
Protocol. LDAP is a light-weight version of that protocol.
It is not clear how to deal with transient inconsistencies, when, for
example, both old and new information floats on the system. Is there an
upper bound to the duration of the transient state? How can we
(eventually) tell the information we received was about to be purged from
the system?
It's not clear what kind of filtering they intended to support in
requests, as shown in 8.2.3.
It's not clear what the use of a context in add or remove requests might
be, in 8.4.
It would be interesting and useful to allow aliasing inside an object
(i.e., to give different names to the same attribute inside an object).
2.61 Descriptive Names in X.500 (Gerald W. Neufeld)
[82] X500 [56] names objects contained in a
directory, using their path location (and assumes a hierarchical
organization): the name of an object is the path to it from the root of
the directory tree. This work tries to assign a better, more descriptive
name to objects that's independent of their path names.
A new piece of information, that was not present in [56] is that
``first-level'' directory service agents, i.e., DSAs that handle subtrees
of the DIT right underneath the root, can also handle the root itself. In
other words, the 0-th level of the tree is handled by all 1-st level DSAs.
The problem lies in that the organization of the directory (who owns what
pieces of it), affects how objects are named. If the directory is
reorganized, all names have to change.
Descriptive names fulfill the following two criteria:
- Order of name components does not matter (in comparison, X.500 uses
a hierarchical path as a name, therefore name components must be ordered
as the tree levels are ordered).
- Not all components must be given (in comparison, in X.500 a missing
components means that the path from the root is broken, resulting in
ambiguity).
Any number of attribute-value pairs that can unambiguously characterize an
object (not requiring that attribute-value pairs belong to the named
object only) can constitute a descriptive name. For example, if we want to
name person X, and we know noone shares X's office phone number Y, then
[office-phone-number = Y] is a descriptive name for office X.
Resolving such a descriptive name can be very expensive. You'd have to
search a lot of the entire tree just to locate one object that matches
all of the attribute-value pairs in the name. You'd also have to keep
looking, just in case there are more matches in the rest of the tree.
Stopping at the first match is not a good solution, since the results of a
query would be dependent on where we start from. For example, if I start
searching at my local domain, perhaps I'll find a local match before I
find remote matches. Different directory user agents would find their
local match first. This is unacceptable, since the resolution of a name in
the directory should have a single semantics.
The solution preferred is one that restricts the tree space to be searched
for a descriptive name. This is done by means of registered
names. A registered name consists of attribute-value pairs that are
protected from duplication outside the owner object. More specifically,
if an object X has a registered name Y whose component is [Z=A], then no
object within the subtree rooted at X's parent may contain Z=A as one of
its attribute-value pairs.
Registered names are used to limit searches for descriptive names within a
subtree much smaller than the entire directory. It is assumed that
most directory system agents that own (i.e., manage) part of the directory
will have at least registered the name of their local root (i.e., the root
of the subtree they own). Therefore, if we find the longest registered
name within a descriptive name, chances are that registered name lies at
the root or within a local subtree of a directory system agent. The search
can be more elaborate within that limited subtree, for the remaining name
components, which are not registered.
Is it clear that subsequent reorganizations of the directory might not
render currently unambiguous descriptive names ambiguous?
The designation of an attribute as a ``naming attribute'' is rather
arbitrary. As shown in more recent work (for example, [1]),
any kind of qualifier might be useful in a name.
It is claimed that descriptive name resolution is no less efficient than
destinguished name resolution. However, it seems to me that the constants
might be very different in the asymptotic similarity. Distinguished name
resolution involves one traversal of the path from top to
bottom. Descriptive name resolution requires one traversal of the
registered path from top to bottom, and then an exhaustive search of the
found subtree (unless very restrictive heuristics are used to guide the
local search).
2.62 The Profile Naming Service (Larry L. Peterson)
[92] Another descriptive naming service, like that in
[82] or [1]. It's a confederate approach, in
that clients are solely responsible for contacting as many name servers as
they need; the name servers themselves don't talk to each other.
An interesting characteristic about Profile is that names are allowed to
contain limited regular expressions instead of merely literal strings. So,
names like ``John|[J[ohn]] Doe'' can be attributed to an object, to mean
any of ``John Doe'', ``J Doe'', ``John'', ``Doe''.
Profile does not enforce a hierarchy unlike most other naming systems. The
sole instrument of low-level organization are attribute-value pairs. The
named objects (principals in the terminology of the paper), have no
relation to each other except for that indicated by an arbitrary
attribute.
The use of multiple name servers in the ``confederacy'' is effected at the
user agent. A resolution operation contains the name to be resolved, the
search path and a bunch of operational flags.
The name is just a set of attributes. It can contain additional
alternation or optionality (is this really a word?) operators. It may also
contain the interpret function that should be used to match the given
name.
The search path is an ordered list of name server addresses known to the
user a priori. This can also be replaced using the indirection operator
``@'' by a list of names naming name servers (lovely sentence...). In
other words, instead of saying ``use the name server at address X'', you
can say ``use the name server by name of 'blah blah blah' ''. The 'blah
blah blah' part is also a Profile name, and the named principal must have
an attribute pointing to the network address of a name server.
The operational flags determine whether the first result or
all results should be returned, and whether the search should proceed
outside the local name server automatically or not.
Name servers can maintain and return referrals to other name
servers. Other than that, they have no organization amongst
themselves. Any kind of name server hopping is performed solely by the
user agent.
The modification API is pretty coarse: users change a public text file and
the database is reconstructed (compiled) from it at regular intervals.
There's also a protected partition for the portions of the database that
should be administered in a more restricted manner. The protected
partition contains most complete attributes (e.g., everybody's user name
etc.) whereas the unprotected partition contains most incomplete
attributes (i.e., things that people want to register for themselves).
There is no defined protection scheme other than that provided by the
systems on which a nameserver relies, e.g., the filesystem.
Using an attribute-based naming scheme has the following pitfalls
associated with it:
- One attribute may describe many principals (e.g., ``name = Petros'')
- Some attributes in the database may not correctly describe the
principals for which they are registered (e.g., ``title = Dr.'' for a
non-doctor)
- Not all attributes that describe a given principal are registered
for that principal (e.g., a principal who has green eyes might not have
registered the attribute ``eye_color = green'')
- Something that sounds like the second pitfall above. I'm not sure
what their difference is in the paper.
Attributes are split into two categories: complete and
incomplete. A complete attribute is defined for all principals in a
namespace. For example, if all principals have a ``name'' attribute, then
``name'' is a complete attribute. This is similar to the closed world
assumption in that, if we know anything at all about a property then we
know all there is to know about that property.
Incomplete attributes are considered less authoritative as name components
than complete ones. An example of how an incomplete attribute can be a
problem is this: Consider principals P and Q and attributes a and
b. If a is registered for both P and Q, but b is only registered
for P, then a is complete and b is incomplete. Now, if a name
contains both a and b, then it is intuitively wrong to not return Qjust because b is not registered for it. To the extent of what is know
about Q, 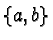 describes it just as well as it does P.
describes it just as well as it does P.
In the Profile world, matching attribute-based names can be done either in
an exact or a partial fashion:
A name (attribute set) A matches another B exactly if A is fully
contained within B.
A name A matches another B partially if the intersection of A and B is not
empty.
Using the concepts of complete/incomplete attributes and exact/partial
name matching from above, Profile defines a set of interpret functions,
aimed at fulfilling different levels of accuracy or selectiveness. As
mentioned above, for example, incomplete attributes are considered less
useful to name a principal than complete attributes.
- 1.
- The first function returns all principals with some attributes in
common with the given name, whether complete or incomplete. This is the
least restrictive interpret function.
- 2.
- Matches are ordered as follows: complete attributes are used before
incomplete ones are used and then exact matches are used before partial
matches are used. So, if the complete portion of the name matches exactly
the complete attributes of some principals, only those principals are
returned. If no such principals exist, then those whose complete
attributes are matched partially by the complete attributes in the name
are returned. If none such exists, incomplete attributes are used instead,
first with an exact match and then with partial match.
- 3.
- Briefly, this function uses the same criteria ordering as the
previous one. Additionally, it restricts the principals returned by
returning those with both incomplete and complete attribute matches.
- 4.
- Finally, this function only returns a single principal matches
exactly on its complete attributes. If there are more than one matched (in
any fashion) they are not returned. This function tries to implement a
traditional lookup function.
The paper describes a way to bake Profile into a Unix shell by using
translation mechanisms that take a standard command (like cp or mail) and
yield a Profile-enabled command.
This paper is in serious need of a translation. It doesn't look like
people who didn't work on it ever read and helped shape its language. The
concepts are not always clearly described, the examples are less helpful
than you'd expect and things enumerated in the text are never given
unambiguous numbers.
2.63 Grapevine: An Exercise in Distributed Computing (Andrew
D. Birrell, Roy Levin, Roger M. Needham, Michael D. Schroeder)
[17] Grapevine is a distributed messaging system, providing
service for service location, naming and authentication. It contains an
early presentation of a distributed email system. The system described
bears close resemblence to how Sendmail and SMTP work.
A basic concept presented here is that of content independence. The
transport mechanism, whether SMTP or the Grapevine transport protocol,
doesn't concern itself with interpreting the content of messages.
End-point applications deal with the interpretation of the payload of a
message.
The level of security described in the paper is weak. A better version
was in the works.
- Experimentation
- Overall service integrity cannot depend on correct client operation
or on the correct operation of all servers. If a client at point A dies,
another client at B shouldn't perceive any functional degradation. If a
server A dies, then a client whose communication is not affected by server
A should not perceive any functional degradation.
- If a message is accepted for delivery, then it will be delivered, or
an error condition will be generated and returned.
- Decentralized administration should be allowed (for tasks like user
admission, control of aliases, etc.)
Users are registered in a database. User entries can be grouped within
group entries. The entry for a user contains an authenticator, a list of
mailbox locations and an address for synchronous communication (mainly
used for server entries - not for people). A user's multiple inboxes are
independent from each other and do not support the abstraction of single
inbox; a user must check all of them for new messages.
Access control allowes an individual to be an owner of a group (in which
case, he may arbitrarily change the entry at will), or a friend of a group
(in which case, he may insert or remove himself from the group).
Only ``signed'' messages may be sent (i.e., the sender must authenticate
himself to Grapevine, before he can send a message). Message polling is
not authenticated. Successful message retrieval may cause messages to be
erased from the protected inbox or retained until later.
Once a message is constructed, the message server authenticates the
sender, flattens out the recipients list (i.e., recursively expands all
groups contained therein) and validates it (returns error conditions for
non-existent recipients). It then receives the message body and dismisses
the user agent. The recipients are then split into ``steering lists'',
i.e., lists of recipients per destination message server. The message is
shipped to each message server once, accompanied by the corresponding
steering list. Transiently undeliverable messages are queued for later
delivery. Race conditions (such as that occurring when a validated user
is removed by the time the message is ready to be delivered) are dealt
with using appropriate error messages, sent to the original sender.
Messages are postmarked with the time at the first-hop message server.
This postmark can be used as a hint for later sorting.
Messages are shared when delivered. When a message is addressed (and
subsequently delivered) to multiple users with inboxes at the same message
server, then the message body is stored on disk only once.
The name space is split in two levels: the top level denotes the name
registry and the bottom level denotes the person within that registry.
Registries are distributed and replicated to multiple name servers.
Replication is at the grain of a registry. Updates can be submitted to
any server containing a registry. That server must propagate the update
to the rest of the name servers serving the same registry.
Servers talk to eachother (for example, to propagate updates) using the
same messaging protocol. So, a server with updated data will send a
message to those server it knows also should hold that data. Servers
check their messages every 30 seconds. Deleted items are retained along
with their deletion timestamp, to deal with cases where an addition and a
subsequent deletion arrive out of order. Every 14 days, deleted items are
purged. Nightly, registration servers perform sanity checks by checking
notes with other servers serving the same registries.
The metadata of the registration database are replicated everywhere. The
metadata registry contains entries for all registration servers in service
(as individuals) and for all registries (as groups of registration
servers). To bootstrap the protocol with a registration server, two
methods are used: an external naming service that resolves
``GrapevineRServer'' to a set of registration servers and a local
broadcast service query.
Resource location works through the registry. Services have their own
groups in some registry. Servers are members of the service they
perform. A client retrieves the membership of a service and then picks
that server which is best, according to some metric.
Caching is used to store hints about where an entry's preferred inbox
lives. If a cache entry is outdated (for example, the preferred inbox has
been removed), it returns a cache flush notification. No other explicit
invalidation takes place.
Some of the administrative functions (for instance, the membership
function) sound inherently extremely expensive (e.g. determining group
membership in a group closure).
A general characteristic of Grapevine is that it understands the semantics
of the registered entries' structure (for example, it knows what a
``connect site'' is, in page 263). Marrying the registry with the
transport module in such a way means that either one (or both) will have
trouble evolving. For example, if the transport changes to a different
protocol that uses more than one ``connect sites'', the registry API will
have to change to accommodate the upgrade.
Authenticating users before messages are accepted implies that there's a
trust base among multiple organizations: If organization A accepts a
message from user B, does that mean that organization C should deliver the
message to one of its users?
Assuming that a human will serialize modifications to a registry is a
rather outdated idea. Global distributed registries cannot be assumed to
be directly serialized by humans any more.
2.64 Experience with Grapevine: The Growth of a Distributed System
(Michael D. Schroeder, Andrew D. Birrell and Roger M. Needham)
[103] Experiences and lessons learned on the system
described in [17].
An interesting point is that Grapevine had an upper limit on how scalable
it should be: 30 servers and 10000 users tops. It is useful to know these
numbers before the design phase.
A significant scaling problem faced the system due to global distribution
lists, whose membership roughly remained proportional to the user
population. Since groups are expanded fully at a message server, before a
group message is dispatched, message addressed to global groups could
result in excessive latency. One way to deal with that would be to add
greater indirection (i.e., intermediate lists within the list), and avoid
total expansion of group memberships. For example, a global list
``news.global'' could be further partitioned into ``news.west'',
``news.east'', etc. In this way, message delivery to ``news.global''
would be offloaded to message servers for the ``west'' and ``east'' (and
so on) registried, parallelizing the task.
Another interesting point has to do with the concept of a moderator in
distribution lists. Regardless of what the system can or cannot do fast
enough, people start getting overwhelmed when, at a point, they start
receiving large numbers of messages.
Duplication of servers (message servers in this case) is not only a
solution for overloading, but also for availability. It's good to have a
local server, dealing with unreliable connections, instead of making the
lack of reliability visible to end users. Registry replica location and
distribution is dependent on five factors, according to the authors:
- Put the data where it's going to be needed: close to he message
servers containing inboxes for the registry
- As before, registries are needed to expand distribution lists: put
the registry server for a group close to a message server accepting
messages for that group.
- Put registries on either side of unreliable links.
- Have enough registries to ensure no data loss (from unexpected disk
crashes).
- Avoid overloading.
A detailed description of the administrative facilities of the system is
provided in the paper.
There are several problems arising from transparent replication. The
paper (in section 6) puts together a list of bad design decisions that
lead to problems, with regards to replication transparency. Below I'm
abstracting the design decisions into a list of things not to do in
distributed systems design.
- The Synchronous Operation Metaphor
- Operations that take a while to
settle (such as the registry update operation in Grapevine) have an
unknown completion time. However, clients (may be lead to) believe that
an update is completed when the first server returns from the update
operation. Either a completion event must be generated when the update is
done, or operation semantics must be modified to convey the rather
user-unfriendly task that they're really accomplishing.
- Distributed Statistics
- Distributed systems don't have to be
unobservable. Statistics about the workings of a complex system are very
useful for that system's maintenance and debugging.
- Growing Pains
- Unoptimized operations which don't happen frequently
are sometimes ignored in unitary systems according to the rule ``optimize
for the common case''. In distributed systems however, if previously slow
operations can become simply unmanageable (because of network latency,
scale changes, fussy failure modes). It's important to figure out exactly
how infrequent an operation is before discarding it as something that
doesn't deserve optimization. A good rule: Sequential lookups are
never good in distributed systems.
- Global Knowledge Assumption
- Assuming that knowledge on the entire
system will be momentarily available (locally or within reach) is highly
miguided. Algorithms should be designed taking under consideration
transient failures and planning ahead for half-way solutions that make do
with what's available.
- Operation Equivalence Assumption
- Assuming, right off the bat, that
reordering the components of a distributed operation (which may be cheap
in the unitary world) leads to equivalent operations is grossly
optimistic. Similarly, arbitrary choice of the location of different
modules in a distributed operation can also lead to inefficiencies. In
the distributed world, the cost of shipping things around becomes quite
more significant than simple local bus operations. For example, consider
task ``A then B'', which consists of subtask A, which takes a lot of input
and produces little output, and subtask B, which takes little input and
produces a lot of output. If I run A far away and B nearby, I have to
ship a lot of input to A's site. If I run A nearby and B far away, then I
only have to ship little data to B's site, after A is done. Obviously,
the latter setup is preferrable.
There are several problems arising from unexpected uses of Grapevine. The
paper (in section 7) puts together a list of encountered problems. Below I'm
abstracting the lessons learned
- Undue Generality
- The designers of Grapevine attempted to simplify
their APIs by, for instance, providing only one way to perform updates:
send the new value and let the recipient merge it with its old value.
However, there are cases, especially in distributed directory services,
when such generality is not helpful: incremental updates should be
allowed, to facilitate updates of BIG values. Simplicity is good,
oversimplification is not (and that's a horrible simplification of the
issue, of course).
- Unexpected Operation
- ``When you have a hammer, everything looks
like a nail''. Using a system for something it wasn't intended can lead
to suboptimal performance. For example, using a naming system essentially
meant for personal, human-timed communications to provide naming in remote
filesystem access can be unhealthy. Operations may take long enough to
frustrate a fileserver, but not long enough to frustrate a human user.
Similarly, if a system is used for random accesses, when designed for
sequential access, neither the system nor the users will be happy.
Here are the lessons learned from the authors' experience in the areas of
reliability and robustness:
- Load Planning
- It is offen difficult to plan against overloading
contingencies. Commonly, when unexpected pathological overloads occur,
cascaded failures due to overloading might ensue. Planning against domino
effects is a good thing.
- Service Quality Guarantees
- To allow for service differentiation,
service discovery algorithms must be selective: not all services are for
everyone. In the example here, if a server is intended as a low-latency,
high-availability server, it shouldn't serve inadvertently clients not
authorized for it. The maildrop facility in Grapevine is a loophole in
service differentiation, causing any kind of selective resource discovery
to fail sooner or later.
The solution to the global distribution list problem is inadequate for a
more scalable system (i.e., one that doesn't such a low upper scaling
limit as Grapevine), since it relies on administrators figuring out what a
good partitioning is, by themselves. Such configuration tasks are better
done automatically, especially if a system is to grow and scale
gracefully.
(In section 7) Using expired cached credentials in the absense of
connectivity is extremely disconcerting. How do we break a file server's
security? We yank the network cable out and then we bruteforce its
capabilities.
It is a common implied stance in this paper to assume that possible bad
things that haven't happened so far won't happen in the future.
Invariably, the bad things in question are pathological conditions caused
by excessive workloads. It is quite naive to assume such conditions won't
occur, should the system is fully deployed, just because they haven't in a
limited deployment of the system. At least, this stance is never spelled
out in the paper.
2.65 What's in a Name? (Peter G. Neumann)
[83] This is a single-page article on naming systems (good
or bad ones) and why it's very important for them to be well designed.
The most important distinction made is between identification and
authentication. The common practice (mainly off-line) of using an
identifier as an authenticator is extremely dangerous and has been proven
harmful. Names, even private names (such as Social Security Numbers in
the USA), are not as good as passwords: names are customarily used as
references (pointers); if one of the places where such a private name is
used as a reference is lax about keeping the reference secret, this entire
fragile authentication scheme falls apart.
2.66 Instant Messaging / Presence Protocol Requirements (Mark Day,
Sony Aggarwal, Gordon Mohr, Jesse Vincent)
[33] This is an internet draft on the protocol requirements of a
common-base personal presence and instant messaging system.
It covers (at the requirement level) such issues as access control of
presence information, notification infrastructure, security affordances,
and so on. This is still a work in progress as of late 1999.
2.67 A Model for Presence and Instant Messaging (Mark Day, Jonathan
Rosenberg and Hiroyasu Sugano)
[34] This is a common model for the IETF IMPP working group's
discussion on Presence and Instant Messaging. It defines such thinks as
the wonderful new term Presentity (i.e., Presence
Entity), Watcher (an agent that looks for changes in a
presentity), Subscriber (a Watcher that waits for future changes)
and Fetcher (a Watcher that just extracts the current value of a
presentity).
2.68 IDentity Infrastructure Protocol (IDIP) (Akinori Iwakawa,
Shingo Fujimoto, David Marvit)
[58] The Identity Infrastructure presented here is an attempt to
deal with the personal communication problem, similar to
[5,101] and others.
What's presented here mainly is the communications protocols between:
- The sender's application and the sender's identity server,
- The sender's identity server and the receiver's identity server,
- The receiver's identity server and the receiver's application
The external IDIP is spoken among identity servers. An identity server
speaks the internal, downward IDIP with an application. Similarly, an
application speaks the internal, upward IDIP with an identity server.
Applications register themselves with their user's identity server, so
that when a request arrives from another identity, this server can
represent its owner's current connectivity state.
No support is provided for content conversion, only for content
negotiation. Location privacy is preserved, although it isn't stated
explicitly in the draft: the draft assumes that identity servers merely
bring end applications in contact with eachother. However, the draft
seems open enough to allow proxies to be used as intermediaries to
preserve users' privacy.
No mention of a personal naming scheme. Email-like identifiers are
assumed.
2.69 Identity Infrastructure and the Extended Individual (Tsuyoshi
'Go' Kanai, Shingo Fujimoto, Katherine Bretz, Dave Marvit, Yoji Khoda)
[61] This is a high-level vision white-paper on the arrival of
``identity services'' as the next killer app.
Much like [101], this advocates the institution of the
``extended individual'', or on-line identity, which represents the person
in the networked world. This identity encapsulates information about the
person (connectivity status, names, etc.), functionality of the networked
person (privacy behavior, for instance) and ``membership information, or
what the paper calls channel (i.e., the addressability of a person
by his interests, capabilities and so on).
2.70 Introduction to Personal Communication on the Internet
(Christian Dreke)
[37] This is an overview of the current available modes of
personal communication (on the Internet).
It goes over communication media both in the real-time category (instant
messaging, text chat, internet phone, and collaborative/whiteboard
applications) and in the asynchronous category (email, newgroups, and
shared spaces).
Then the author proceeds to present the application contexts within which
these communications media are combined into personal communications
applications. Buddy lists are systems where a person subscribes to his
circle's members; when a member ``comes on-line'', the subscriber is
notified. This is the general framework within which On-line presence
work is being conducted (see also [34]). Other such contexts
include internet telephony, virtual communities (e.g., multi-player
gaming, real-time newsgroups/topicgroups), and virtual worlds.
The main barrier preventing these applications from becoming predominant
is standardization, especially in the Instant Messaging/Presence arena:
there are too many proprietary protocols striving to secure a market
share, completely precluding interoperability among all users' software.
2.71 Enterprise Identity Management within the Digital
Nervous System (Microsoft Corporation)
[30] This is a corporate strategy paper, which
addresses the issue of identity management within the limited scope of the
Enterprise.
2.72 A Logic of Authentication (Michael Burrows and Martín Abadi)
[20] This is an attempt at designing a logic for reasoning
about authentication mechanisms.
The main constructs on which the logic is based are as follows:
Using these constructs and some common sence rules about authentication,
a set of inference rules have been put together:
- Message-meaning. If P believes
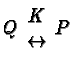 and P
sees
and P
sees 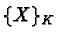 ,
then P believes Q said X. Similar rules exist for
public key encryption and for shared secret authentication.
,
then P believes Q said X. Similar rules exist for
public key encryption and for shared secret authentication.
- Nonce verification. If P believes fresh(X) and P believes
that Q said X, then P believes that Q believes X.
- Jurisdiction. If P believes that Q controls X and P
believes that Q believes X, then P believes X.
- Key use. If P believes
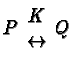 and P sees
,
then P sees X. Similar rules exist for public keys and
shared secrets.
and P sees
,
then P sees X. Similar rules exist for public keys and
shared secrets.
- Superset Freshness. If a subset of a set is fresh, so is the
set itself. In other words, if P believes fresh (X) then P believes fresh
(X, Y).
Some additional rules dealing with instantiation of variables and other
inference tools are also included.
To use the logic described above to derive facts about authentication
protocols, a transformation of those protocols to the vocabulary of the
logic must first be performed. The transformation was arbitrary and
interpretational in this paper, i.e., there was no formal method to
perform it.
Given a protocol, once its idealized protocol counterpart is derived
(i.e., its equivalent protocol in the vocabulary of the logic described
above), the inference rules may be applied to it, to derive a concluding
set of facts about the protocol: a set of opening assumptions are stated,
which are augmented by inferred facts after each step of the idealized
protocol. The goal of this process is to prove in the end that both
parties of an authentication exchange have a common shared key for
subsequent communication (i.e., A believes
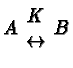 and B
believes
). Some times, a stronger goal is necessary
(or possible), namely that both parties know that the other party has the
same information about the exchange as they do, i.e., A believes that B
believes
and similarly, B believes that A believes
.
and B
believes
). Some times, a stronger goal is necessary
(or possible), namely that both parties know that the other party has the
same information about the exchange as they do, i.e., A believes that B
believes
and similarly, B believes that A believes
.
The authors proceed to apply their logical analysis to:
- The Kerberos protocol [107]. Freshness of nonces is
dependent on synchronized clocks, which tends to be a bit of a problem in
practical implementations (especially since secure time servers are not
widespread).
- The Andrew secure RPC handshake. Here a weekness is discovered,
where one of the participants may be prone to replay attacks.
- The Needham-Schroeder public key protocol [80]. The
authors discover a weakness in the interaction of principals with the
certification authority (they arbitrarily believe the freshness of
messages coming from the CA).
- The X.509 protocol (version of 1988). Here both redundancies and
weaknesses are discovered. The weaknesses stem from facts stated in the
X.509 specification which contradict what seems to be assumed in the
protocol (namely, an arbitrary freshness decision about one of the used
nonces).
The constructs and the mechanics of the paper are pretty interesting,
although lots of pieces are missing, most notably the transformation
mechanism into idealized form.
2.73 Authentication in Distributed Systems: Theory and Practice
(Butler Lampson, Martín Abadi, Michael Burrows, Edward Wobber)
[68] This is an extremely dense paper describing a detailed
theory for authentication and its practical applications.
Principals are the main acting entities in this authentication
theory. Principals can request actions. Actions are performed on
objects (resources such as files, devices, processes, etc.). The
objective of this work is to provide a language in which rules may be
defined, according to which requests by a principal on an object are
granted or not. Rules are attached to the objects they govern. A
reference monitor decides whether to allow a specific action,
taking under consideration the involved objects with their associated
access rules, principals and requests.
The job of the reference monitor is non-trivial, especially in distributed
systems, since it must make logical inferences leading it to a decision.
For example, principals almost never directly attempt an action on an
object themselves, since principals are humans and objects are bits; most
usually, a principal utilizes a channel, such as a network
connection, a pipe or a function call (e.g., to access object X, Alice, a
principal, types on a keyboard, which is attached to a system K, connected
through a TCP pipe P to another system L, where object X lives. The
reference monitor on system L sees an action attempted by a process Z on
object X.) Channels are principals, too; however, they're more than that,
because they can request things directly inside a computer, whereas human
principals can't.
The reference monitor must decide whether the immediate channel attempting
an action is trusted at least as much as the principal mentioned in the
access rule for an object. In the example above, if X specifies in a rule
that it will accept all actions from Alice, then the reference monitor
must decide whether process Z is at least as trustworthy as principal
Alice. To do that, it has to reason about Z, L, P, K and Alice.
Trust can be bestowed or transfered by a principal on another principal.
For example, I may trust my brother to do anything that I can do. To
prove my trust, I give my brother a legally binding document, such as a
power of attorney. This provable trust is represented in the
authentication theory described in this paper by the ``speaks for''
relation. When A speaks for B, A can do at least as much as B can do
(i.e., if a request should be granted for B, then it should also be
granted for A). Since only channels can say things directly inside a
computer, invariably human principals must have channels that speak for
them, so that they can communicate their requests through a computer
system.
In a distributed system, where many components from different devices
conspire to see a request through to its destination, it is inevitable to
place different levels of trust in the reliability or the loyalty of every
single component. A well-designed authentication system relies for its
security only on few trusted components, its Trusted Computing
Base, or TCB; in other words, no component outside the TCB should be
allowed to affect the security of the system by misbehaving. Furthermore,
the system is fail-secure when it is conservative in the face of
failure: when it gives the wrong answer, it always denies a request it
should have granted, never the other way around.
To connect principals to other principals, define statements, etc., the
following constructs are possible:
- Speaks for
-
 means that if A does something, it is
exactly as if B had done the same thing.
is a statement.
means that if A does something, it is
exactly as if B had done the same thing.
is a statement.
- Quoting
- A|B means that A says that B does something. A is
quoting B as doing or saying something. Keep in mind that A might be
lying (so B might not in fact do what A quotes B as doing). A|B is a
compound principal.
- Says
- (A:s) is a statement, representing the fact that A says
statement s, or A is entitled to claim s. A may or may not have
uttered s, but we can proceed as though A actually has. In other words,
as far as A is concerned, given his knowledge and capabilities, s holds
true.
- Aggregation
 is a compound sentence, consisting of both
s and t. Similarly
is a compound sentence, consisting of both
s and t. Similarly  is a compound principal, consisting of
both A and B.
is a compound principal, consisting of
both A and B.
Some basic, intuitive axioms or inference rules using the above constructs
are defined in the paper, including modus ponens, distribution and
monotonicity over
 of ``says'' over
of ``says'' over  and so on.
and so on.
One of the primary tools in this theory is the ability to express
delegation of authority. A principal can utter a statement that allows
another principal (most commonly, a channel) to speak for it. The main
handoff rule is
The
handoff rule can be expressed even more powerfully (without asserting
more), by making the initiator of the handoff be a principal who just
speaks for the owner of the handed off authority, i.e.,
Encrypted channels are very powerful. They allow the untrusted, arbitrary
handling of messages, without compromizing the contents' secrecy or
integrity, through public key cryptography. Even if existing public-key
cryptographic algorithms turn out to be insecure or too expensive,
shared-key cryptography can be used to simulate public-key functionality.
Therefore, even with a small TCB, a sane authentication model can be built
using encryption.
Given that a computer node is trusted as a whole (including its operating
system and administration), the first step to building secure end-to-end
channels, for use in the authentication scheme described, is to build
secure channels from node to node. A single node-to-node secure channel
between any two nodes is sufficient, since the theory allows multiplexing
over a single channel. The node-to-node scheme must allow rekeying (since
encryption keys must change regularly).
The authors present the following mechanism to establish secure
node-to-node channels (from A's view point; B does the symmetric). It is
assumed that both A and B have their own node key-pair, which has been
assigned to the node by a certification authority, and their own boot key
pair, computed when the node boots up.
- A sends its own public boot key to B (Ka).
- A computes a random symmetric key (Ja) and sends it to
B encrypted with B's public key Kb, i.e securely (
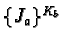 ).
).
- A puts together the two symmetric keys (Ja, which it just made
up, and Jb, which it received from B) and creates a new symmetric key
K to use in its secure node-to-node channel with B. Instead of
concatenating the two, it uses a one-way hash function on the
concatenation, to avoid known-plaintext attacks. The new key is
K =
h(Ja, Jb).
Up to this point, A and B can communicate using K, up until they have to
change keys, or one of them dies. However, to be able to talk about this
channel, they have to name the key they're using (so that, for example,
innocent or malicious replays may be identified). To create an identifier
for this newly created key, they take the next step.
- A encrypts K with a secret, private master key KaM and sends
it to B. This is A's identifier for K. Together A's and B's
identifiers for K define this secure channel between A and B completely.
Note that any arbitrary way of creating an identifier for K (with
minimal conflicts) would also do.
After this exchange, A knows that
 ,
i.e., everything
that arrives encrypted by K can be safely trusted as much as anything
that could arrive encrypted by Kb-1. Since Ka and Kb are not
used by the actual channel, they can remain in use for much longer (as
long as the system stay up in this case) and still, the channel bears
their trust.
,
i.e., everything
that arrives encrypted by K can be safely trusted as much as anything
that could arrive encrypted by Kb-1. Since Ka and Kb are not
used by the actual channel, they can remain in use for much longer (as
long as the system stay up in this case) and still, the channel bears
their trust.
To extend the chain of trust a little bit further, we need to show that
someone ``meaningful'' sits behind Ka. That can be done by connecting
the A's node key to Ka. Remember that Kan bears a certificate
that
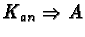 ,
for the ``meaningful principal'' A. Now, if
node A can present something like
,
for the ``meaningful principal'' A. Now, if
node A can present something like
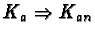 (for example,
sign Ka with
Kan-1), then Ka can be trusted as much as
Kan, or transitively, A.
(for example,
sign Ka with
Kan-1), then Ka can be trusted as much as
Kan, or transitively, A.
RIGHT BEFORE 5
2.74 Development of the Domain Name System (Paul V. Mockapetris and
Kevin J. Dunlap)
[77] How the Domain Name System was born.
In the begining, there was the HOSTS.TXT file. This was a file
whose lines contained an association between a name and a network address.
This file was centrally maintained and distributed to all hosts on the
network periodically. This worked fine, while there was a single,
humongous host per organization; when, however, host numbers started
paralleling user numbers, HOSTS.TXT became a huge administrative
bottleneck: centralization was incompatible with the higher rates of
change.
The main constraints that the DNS design strived to uphold were
- to provide at least as much functionality as the old method
- to permit distributed administration of the database
- to make name extensible and practically limitless
To deal with the distribution requirements, a hierarchical name space was
chosen. Since this was a project intended for immediate deployment,
trade-offs between the lowest common denominator approach and the
featurerama approach were biased towards the former. A leaner protocol
would have fewer points on which objections could be based.
The main components are the name servers and the resolvers.
The former maintain the information and answer queries. The latter live
on the client side and talk to client programs; they run the algorithms
necessary to locate the name server with the sought information. The
introduction of separate resolvers in the architecture was intended to
facilitate use of the protocol by clients with very limited resources.
Such clients could share a resolver.
2.75 Efficient and Flexible Location Management Techniques for
Wireless Communication Systems (Jan Jannink, Derek Lam, Jennifer Widom,
Donald C. Cox, Narayanan Shivakumar)
[59] One interesting aspect here is that they are trying to
motivate life long numbering. there is no actual motivation behind life
long numbering; instead a viable way to obtain life long numbering is
provided.
Life long numbering is provided by a hierarchical database scheme. Higher
level databases store pointers to lower level databases. Leaf databases
store the actual profile. Every database must contain a pointer towards
all profiles included in its subtree. The top level database must contain
pointers towards all existing profiles.
Queries start from the database of the caller going upward until a pointer
to the callee is located (This happens for the first time in the database
that is the least common ancestor of the caller's and the callee's
databases); then the search proceeds downward.
Hiper is using this hierarchical architecture along with replication to
both provide life long numbering and minimize query and update latencies.
The location of replicas is determined in a way similar to that described
in[Shivakumar 94], modified to hierarchies instead of graphs. The number
of replicas is determined from the available database space allocated to
each of the systems users. Additionally, the more replicas there are in
the system, the higher the update cost. Therefore, the number of replicas
per person should be limited.
Replicas are placed in the hierarchy to minimize the update cost while
minimizing the lookup cost. A useful metric for calculating those costs is
one for calling frequencies between the sites of two people participating
in a communication. This is called the local call to mobility ratio. It
is defined as the number of calls from a user to a zone over the number of
moves of that user in a fixed time period. When this number is high, it
makes sense for the calling zone to replicate the profile locally. This
ratio can be compared to a threshold to determine whether that user's
profile will be replicated in the called zone.
Since ancestor databases contain the covered area of all their descendant
databases, the local call to mobility ratio is always higher than the
threshold in the ancestors when it is higher than the threshold in a leaf.
So, naively, it would seem beneficial to replicate all profiles at as high
level a database as possible. Unfortunately, higher level databases
service more profiles than lower level databases which means that the
update costs incurred could overwhelm them. A tradeoff has to be
maintained between overwhelming higher level databases with updates and
populating the hierarchy with ineffective profile replicas.
For high enough values of the local call to mobility ratio, replication
can be considered justified. Similarly, for high enough values of the
ratio, replication can be considered unjustifiable. For the values in
between,replicas could be allocated in the most beneficient way, i.e., so
that only those with highest ratio among the non- clearcut databases get a
replica. The upper and lower threshold values are picked to unambiguously
make replication good or bad.
The algorithm described in the paper first assigns replicas to as many of
the databases with a ratio above the upper household as possible, starting
from the bottom of the hierarchy, until all such databases are given a
replica or the maximum number of replicas has been assigned. In the
second phase, the rest of the unassigned replicas are allocated to
databases with as high a ratio as possible, starting from the top.
Another contribution of this paper is a fairly elaborate framework for
simulating location management techniques. The simulator takes under
consideration geographical features like freeways or local population
sizes, when implementing user mobility and calling patterns, as well as
network computing between sites.
The actual simulation setup in section 4 of the paper is a very
interesting combination of statistical national averages with local
counters in a simulation.
It is unclear why this algorithm was picked. Especially, it is unclear
why exactly all of the second phase replicas are assigned top down, or why
the split between bottom up and top down assignments is set to be the
upper ratio threshold.
One big hole in the paper is the lack of proof of scalability of HiPER
compared to other schemes. The authors admit that all their simulated
systems are nothing special given current hardware and software.
2.76 An Analysis of Wide-Area Name Server Traffic: A Study of the
Internet Domain Name System (Peter B. Danzig, Katia Obraczka, Anant Kumar)
[32] A major difference to current trends in this paper is
its pre-web approach to Internet wide traffic. They say that the
predominant source of request/response traffic on the Internet comes from
name server traffic. This is not true any more in post-web times, in all
probability.
The basic issue dealt with here is how DNS was flawed, how that led to
performance problems, and how the problems could be solved.
One of the implementation and deployment issues observed is the
predominance of collocated caching-only servers with client resolvers.
The absence of centralized caches within a site, that could share name
caches among multiple local resolvers, leads to multiple queries issued
for the same result from the same site.
The paper includes a technique for calculating the packet loss rate on a
single ethernet, given the numbers of unmatched requests and responses for
local queries.
It seems that the paper is less applicable to directory services other
than the DNS, especially since it tends to focus on DNS bugs and how they
have been manifest (for example, some resolvers' mistake of adding the
local domain name to all queries, assuming client programs always gave
them unqualified host names).
An interesting contribution of the paper is a classification scheme for
server errors (bugs, incorrect assumptions, etc.). One of the conclusions
drawn is that negative caching is in general overstated, mainly because it
is intended as a safety valve for faultyimplementations of servers or
resolvers.
An interesting data point is the amount of replication per directory unit
in a large set of servers. The authors use these data to support "unfair"
leak of performance degradation between multiple domains serviced by the
same server.
The authors claim that active error detection is more important than
widespread deployment of bug free implementations. The reason is that
bugs may resurface, despite the efforts of programmers. Active error
detection can limit the impact of current or future bugs. One proposed
technique is "playing dead". According to it, a name server can
occasionally play dead for a particular queried name and record the
requester's reaction. This can show problems like untuned retransmission
intervals, for example. Another approach would be to keep track of how
many times the same query has been submitted by the same client host.
Erratic hosts can be identified in this way and notified of their errant
ways.
2.77 RFC 1484: Using the OSI Directory to achieve User
Friendly Naming (OSI-DS 24 (v12))
(S. Hardcastle-Kille)
[46] This scheme is intended to provide user-friendly naming
within a larger directory service, such as X-500. The distinguished name
of an entry is separate from the user-friendly name for the same entry.
The distinguished name is a unique identifier, whereas the user-friendly
name may omit features of the entry that don't interest the requester.
The scheme is heavily dependent on X.500, which is in turn heavily
dependent on organizational structure. User-friendly names are reduced to
their structure using defaulting rules, for instance, when the inferred
country is USA, then a two-letter component preceding it is assumed to be
a state.
There is a long list of heuristics used to resolve a user-friendly name to
a distinguished name, assuming that the user-friendly name follows certain
conventions, such as hierarchical ordering. Perhaps in current technology
that deals with searches of large distributed data stores, such heuristics
wouldn't necessarily be of much use.
One important advantage of this scheme is that, similarly to X.500, it
doesn't have to invent a new name for an entry. Instead it uses the
commonly used name for an entry. Unfortunately, some entries may share
the same "commonly used name", for example roles of the same person, or
people with the same name. To resolve such ambiguities, much longer names
would have to be devised.
It seems that this scheme is merely a glorified method for resolving a
local alias to the globally unique name for an entry. The resolution
takes place locally and might come across ambiguities when transferred to
a third party.
2.78 A Location Management Technique to Support Lifelong
Numbering in Personal Communications Services (Derek Lam and Yingwei Cui
and Donald C. Cox and Jennifer Widom)
[66] One obvious change from the previous paper
([59]) is that online, as opposed to offline, replication is
investigated. In other words, replication decisions are made while the
system is in operation.
A new thing in this paper is a reasonable albeit slightly fluffy method
for maintaining the metrics used to calculate the local call to mobility
ratio.
In this online version of the scheme (called Hopper), the threshold
variables are replaced by a threshold variable for creating a new replica
and a threshold variable under which a current replica is removed. The
values of these thresholds can tolerate non-optimality, as the simulations
show. The thresholds for replication and deletion are picked from the
basic cost inequality, comparing update cost and lookup cost for any two
pairs of zones. Values are picked by instantiating the hop distance
between the caller and the callee with their minimum and maximum values
respectively. In other words, what used to be the lower threshold in the
offline case, becomes the delete threshold and what used to be the upper
threshold in the offline case becomes the replicate threshold.
The scheme uses a time threshold to determine when calling or mobility
measurements are too old to use. When the time threshold elapses, calling
and mobility measurements are flushed. To make sure that early estimates
after a metric flush are not too inaccurate, calling and mobility
measurements are not used to calculate new ratios until their sum
surpasses another predefined Threshold.
When after a lookup, it is determined that the caller deserves a replica,
but there are no more replicas available to create there,then the replica
exchange protocol is used. This is done asynchronously. During this
exchange, a random replica is considered for deletion. If the randomly
selected replica is not as beneficial as the caller's, then the former is
deleted and the latter is notified that it currently contains a replica of
the profile in question. The exchange is not performed if it's going to
cause excessive transfer costs, for example if it has to travel too far,
or the system is currently overloaded. Replicas may also be deleted
during updates. If when a replica is updated with a move, it determines
that it no longer surpasses the deletion threshold, it notifies the
previous current location of the profile that it has removed itself from
the replica set.
Another departure from the previous, offline algorithm, is that replicas
are now only placed into leaf databases. The authors justify this choice
with its lower complexity, especially in the case of online replica
allocation.
The simulation part of the paper presents a multi-day run involving the
ten most populous cities in the USA. The basic home location registry
technique (with translation for lifelong numbering), basic home location
registry with caching, simple hierarchical, HiPER and Hopper are
simulated. The simulations show that Hopper can achieve fairly consistent
lookup locality, due to its online nature, while maintaining low
requirements on database storage.
2.79 Designing Directories in Distributed Systems: A Systematic
Framework (Chandy, K. Mani and Schooler, Eve M.)
[22] This work seems to be attacking directories from a
knowledge-theoretic point of view. The idea is to use directories in a
distributed system to share information about processes among processes,
given constraints on latency and overhead. When constraints limit the
amount of knowledge sharing, then knowledge estimation is used.
The concept of process knowledge, as defined in the theoretical
literature, is too strong to cover practical distributed systems. The
problem is that "knowledge" is too strong a word. Traditionally,
knowledge of a fact X about process B by process A means that fact X is
true about process B. Unless something is done by process A to change its
X-knowing state, fact X will have to remain true regardless of process B's
will. Since in practical systems the state of process B can change with
or without A's consent, the concept of knowledge cannot be supported.
An argument is made about the dependency between global clocks and
knowledge gain or loss. The argument is connecting the fact that if I
know X is true between times a and b, then at time a I gain the knowledge
that x is true, whereas at time b I lose that knowledge. However, that
seems a bit naive, since the knowledge was "x is true between times a and
b" all along; the knowledge is not lost after it has become
non-applicable. A minor philosophical point.
Estimation is based on conditional probabilities. In practical systems, a
process can know a fact about another process only with a probability
lower than 1 usually. This work tries to derive useful conclusions from
sets of such probabilities connecting different facts in a distributed
system.The goal for a designed directory would be to optimize the estimate
probabilities for the contained properties, for a given set of
infrastructure constraints. Problem-specific properties, such as temporal
or spatial locality can affect how these estimate probabilities vary.
Moreover, ways to increase probabilities are explored, as well as the
price incurred.
The directory design space is broken into two axes: organization
(centralized, hierarchical, distributed) and maintenance (active or
passive, push or pull).
- centralized directory: this is good when the sources of information
live near the directory, or the overhead per source is low, or updates are
relatively infrequent. Scaling and reliability are two major concerns
about centralized directories.
- hierarchical directory: this is good for cases where common
directory lookups are limited within a restricted-scope sub directory. In
those cases, answers of higher quality (higher estimate probability) can
be requested from higher levels of the hierarchy, which may be more
expensive to access.
- distributed directory: this provides the greatest immediacy of state
information, provided that applications permit inconsistencies among
directories or require only eventual consistency. Distributed directories
can only be viable when data replication is relatively inexpensive and the
aggregate overhead in communication does not overwhelm the infrastructure.
- passive or periodic update (push or pull): prearranged updates are
good when the period of validity of the transferred information is known
in advance or when the information consumer needs periodic affirmation of
this validity. The actual time period need not be static; it may adapt to
current conditions or needs. However, the tradeoff to consider is between
empty (i.e., redundant) updates and the cost of update requests.
- active push: this happens when the reporting process lets the
directory know of a significant state change. Since updates are pushed to
the directory, and perhaps subsequently pushed out to subscribers to those
updates, only useful update messages are propagated. However,if an update
is lost due to infrastructure unreliability, it may be completely missed
by those interested until the next significant update comes up.
- active pull: this makes sense when there are far more information
consumers with far more requests than information producers and state
changes. In those cases, the directory belongs near the requesters and
the producers may be far away.
The paper proceeds to describe the simple case of a two-state process
communicating with a directory, in both lossless and lossy communications
environments. Finally a specific case study is presented for a
videoconferencing application.
2.80 Recommendation X.501: Data Networks and Open System
Communications - Directory: Models (ITU-T)
[57] This standard describes exactly how things are modelled inside
X.500 ([56]).
An administrative domain, as far as X.501 is concerned, consists of
multiple subtrees not necessarily communicating with each other. This
means that the domain may control multiple subtrees routed at different
points of the global tree.
X.501 seems to have a strange fascination with administrations of the
national level. They even make the distinction between the domain
belonging to a national "administration" (and administration is the
national telecommunications carrier) and private administrations. They
even go so far as mentioning national regulations governing
administrations within the barriers of a single country.
The specification recognizes the existence of multiple roles of a single
person. They don't go far enough to define a correspondence between real
objects (i.e. the real world) and online objects.
The administration of the directory is served by entries in the directory
itself. Although those entries are mentioned as "administrative entries",
they look exactly the way other normal entries look.
Attributes types may be subtyped. Every entry in the directory, contains
an attribute type and a list of values (non empty). A value may be
annotated with a context. A particular entry may have many alternative
values for various contexts. A common context is language.
Additional object schemas may be defined, beyond those standardized by
central organizations, national organizations or private organizations.
It is not clear how easy to do that will be.
Besides attribute types, there are also object types. Those are also
subtyped. Multiple inheritance is supported.
There is a fine distinction between what is called a structural object class and an auxiliary object class. Roughly speaking, the former is an interface whereas the latter is an implementation. Structural object classes represent the way an entry looks inside the directory. An associated auxiliary class determines the semantics of that entry.
In section 8.8, matching rules are discussed which are used for searching
through the directory. Although a set of basic matching rules is defined
in X. 520, no restrictions are placed on the kind of rules supported in
X.500. The most basic rule is an attribute-value assertion. This checks
an entry for the presence of an attribute and compares its value with that
given in the assertion. Such rules may have a context associated with
them, so that a particular instance of the sought attribute is checked.
Every attribute type contains its own equality matching rule (somewhat
like the equals method in Java). That can be used in attribute-value
assertions. Rule evaluation is extremely flexible, to allow the same rule
to match different things depending on where the directory resides. For
example, if no context preference has been included in an assertion, then
the context may default to what the particular answering directory
considers default. Builtin rules include presence, equality, ordering,
substring matching, and approximate matching.
Section 9: A name is a sequence of Relative Distinguished Names. X. 501
acknowledges that alternate ways to name objects in the directory are
possible in the future. An RDN is the set of attribute value pairs in an
entry of all those attributes which have a distinguished value. If an
attribute doesn't have a distinguished value then it doesn't participate
in the RDN of its enclosing entry. An entry may have multiple RDNs if
some of its distinguished values has instances for different contexts. An
RDN is modifiable.
Among the multiple RDNs for an entry, one is designated the "primary" RDN
for it. It consists of the primary attribute value pairs for all
participating distinguished attribute value pairs. This primary RDN,
which is unique for an entry, is what most directory operations would
normally return.
A distinguished name for an entry is the sequence of RDNs from the root of
the directory to the entry, through the hierarchy. A distinguished name
for an alias is not the same as the distinguished name for the entry the
alias points to. Clearly, a primary distinguished name for an object is
that consisting of primary RDNs.
Alias entries are always leaf nodes. They do not have to point to the
name of a real object necessarily.
Section 10: Administered areas are partitions of the global tree that are
administered by a single administrative organization. For example, the
subtree belonging to the U.S. constitutes an administrative area
administered by the actual organization in the U.S. dealing with its share
of the X.500 global hierarchy. The root entry of such a subtree is the
administrative point.
Inside an autonomous administrative area, there are four kinds of specific
administration supported: for names(i.e., deciding which names can or
cannot be given), schemas (deciding how governed entries will be
structured), security and collective data. Specific administrative areas
deal with subtree schemas, security (i.e., access control), collective
entries and default contexts (i.e., which context will be considered the
default one, when the default context is needed).
Areas dealing with specific kinds of administration among those above may
overlap; for example an administrative area that deals with security might
overlap with a different administrative area that deals with the default
context. A domain as described above consists of potentially multiple
autonomous administrative areas.
Section 11: A subtree refinement is defined as a subtree, whose shape has
been carved either by depth (i.e., excluding a number of upper levels and
or lower levels), by name (i.e., excluding a number of its subtrees with
or without the subtree root) or by type (i.e., excluding or limiting to a
set of entry types).
Section 12: A directory schema, associated with an administrative area,
contains information about the kinds of names possible in the area, the
possible object classes, attribute types, matching rules, contexts,
associations of attributes to possibly containing object classes, and
possible associations of object classes with subordinate object classes in
the hierarchy.
Class hierarchy is explicit in the directory. More specifically, every
object contains the identifier of all the superclasses of its own class.
This need not necessarily be reflected in the actual storage. The
directory does make sure that entries of a particular object class follow
the rules (contain all the mandatory attributes, do not contain
unanticipated attributes, do not allow multiple values in singleton
attributes and so on).
Attribute types contain information such as their superclass, their
syntax, matching rules, whether they are operational (i.e.,
meta-informational) or user controlled, whether they are collective or not
and whether they are singleton or not. Operational and user attributes
form separate hierarchies. Attributes lacking equality matching rules
cannot be used for naming and lose their type when queried.
To fully specify the structure of an administrative area, its
administrative point will contain enough subentries describing allowed
structural classes, their naming and their content rules. Name forms are
assigned to an object class and determine which of the mandatory or
optional attributes of that class can be used in its RDN.
Structure rules specify how entries can be linked to each other in the
hierarchy within an administrative area. They associate a name form
(which, in turn refers to an object class) with a set of possible superior
structure rules (which, each, point to object classes as well). For
example, to make it possible for an entry of object class A to have a
subordinate entry of object class B, first a name form for class A has to
be created, let's call it name form C, that defines an RDN scheme for
class A, and then a structure rule D for name form C (connecting it to its
superiors). Then, a name form E for class B should exist and a structural
rule F containing E as its name form and designating structural rule D as
its superior rule.
The actual contents of an entry within the specified administrative area
are dictated by a content rule. A content rule takes a particular object
class and turns it into a specialized/customized class for this
administrative area. It can give it additional mandatory and optional
attributes (beyond those defined in the class definition), specify
additional auxiliary object classes ("implementation" classes), and
preclude some of the inherited optional attributes from appearing.
Finally, contexts within the area are defined in two phases: context types
are primary, fundamental contexts that can be used within the area. Those
are defined independently of the attributes where they may apply. In the
second phase, context use rules associate an attribute with a set of
mandatory contexts (they all have to be defined whenever this attribute is
met in the area) and a set of optional contexts.
Section 13: The directory system schema is defined within an area to
determine how administrative and operational properties of area can be
included. It determines the kinds of subentries that may be created and
defines operational attributes for the area. So it deals with subentry
name forms. Other operational attributes include timestamps, creator or
actor identities, associations of entries with their governing subentries,
access control, context assertions.
Section 14: In this section the actual structure of a subentry is
described and how all pieces of schema information from sections 12 and 13
come together into the subentry of an administrative point.
Section 15: Authentication procedures work through the association of a
user identity and an access control identity. The latter is used in all
access control decisions.
An access controlled specific administrative area is governed by the
access control scheme defined in a subentry of its administrative point.
All arguments, results or errors in directory operations may use a
protection mapping. There are three defined protection mappings: signing,
encryption, and signing-and-encryption.
Section 16: Several access control schemes can be utilized inside the
directory, to suit the requirements of the current administrative area.
Basic access control is fairly flexible and somewhat complicated. Simple
access control is a subset of basic access control. Rule-based access
control can setup procedural kinds of access decision functions.
In access control schemes, access control items are the basic units of
control specification. They can be placed at various locations throughout
an administrative area, with different semantics. Sets of them can be
combined and precedence is defined among access control items in a set
according to an integer priority. An item can have different levels of
fidelity requirements placed on the authentication of the requester of an
operation. Specifically, the identity of the requester might have no
fidelity (i.e., we assume the requester is who it claims to be), simple
fidelity (i.e., password based) or strong fidelity (i.e., based on strong
authentication).
Access control can apply to a number of different kinds of "protected
items". Such are entire entries, attributes, attribute values or names.
More specific instances of those may be specified as protected items, such
as "all attribute values of attribute X". additionally, access controls
can be associated with constraints, such as "do X if by doing so there
won't be more than y values for attribute z".
Permission categories include standard permissions like read, browse, add,
modify, permissions for moving entire subtrees to a different location,
for using attributes or attribute values in filter matches etc.
Permission items can apply to an entire administrative area (in which case
they are called prescriptive and are placed within a subentry of the
administrative point), to the subentries of an administrative point (in
which case they are called subentry and are placed within an
administrative point), or to a single entry (in which case they are placed
within the entry itself). When making an access control decision, all
access control items of the scope within which the protected item resides
are taken under consideration. Those are the entry item, if one exists,
and all prescriptive items for all administrative areas within which the
item lives, up to the top of an autonomous area. Similarly, for a
subentry, its own entry item, its owning administrative point subentry
item and all superior prescriptive items up to the top of an autonomous
area are taken under consideration.
A general rule governing how basic access control schemes operate is that
any access control decision should be answerable without having to inquire
remote directory system agents.
The ``simplified access control'' scheme is the same as the ``basic access
control scheme'', except that it doesn't support inner security areas
(i.e., no nesting) and it doesn't support access control items within
single entries.
Section 17: In rule-based access control schemes, access control
associated with specific data is not explicit. Instead, a general label
indicating how restricted a piece of information is is attached to the
relevant entry. This label along with the properties of the requester and
the policy used determine whether access will be granted or not.
Section 18: X.500 provides support for maintaining integrity information
within the directory. This is done by supporting digital signatures
within the directory along with the information itself.
Similarly, X.500 provides support for maintaining confidentiality of the
stored information (i.e., keeping stored information secret even from the
directory itself). This is done by designating stored information as
encrypted using a particular algorithm.
2.81 Global Internet Trust Register
[2] This book contains fingerprints for some of the most
important public keys used on the Internet at the time of its publication
(early 1999).
The reasons for putting the functionality of a global CA into paper form
have been to
- offer a reasonably neutral top-level CA; commercial ones tend to
avoid talking about their competitors
- capitalize on our instinctive trust of print over electronic
publishing
- use the political privileges of print publishing, over electronic
publishing, in the face of proposed government licensing or control of
CAs.
X509 and PGP key fingerprints are included. The keys have been given a
level trust, ranging from D (minimal trust) to A (full personal trust).
In the process of accumulating the keys printed within this book, the
editors have identified some ominous problems in the way that certificates
are handled in web browsers. They have unearthed implementation flaws
(giving incorrect results), design flaws (ignoring important
protocol-mandated fields from certificates), distribution flaws
(hard-coding root CA keys into the application, whose lifetime might
surpass the lifetime of the hard-coded CA key).
This is version
$Id: Bibliography.tex,v 1.53 2000/06/20 03:14:52 maniatis Exp maniatis $
- 1
-
William Adjie-Winoto, Elliot Schwarz, Hari Balakrishnan, and Jeremy Lilley.
The design and implementation of an intentional naming system.
In Proceedings of the Seventeenth ACM Symposium on Operating
Systems Principles, pages 186-201, Kiawah Island, SC, U.S.A., December
1999. ACM SIGOPS.
>>>>>>.
- 2
-
Ross Anderson, Bruno Crispo, Jong-Hyeon Lee, Harry Manifavas, Vaclav
Matyas Jr., and Fabien Petitcolas, editors.
The Global Internet Trust Register.
MIT Press, 1999 edition, March 1999.
ISBN 0-262-51105-3 >>>>>>.
- 3
-
Thomas E. Anderson, Brian N. Bershad, Edward D. Lazowska, and Henry M. Levy.
Scheduler activations: Effective kernel support for the user-level
management of parallelism.
ACM Transactions on Computer Systems, 10(1):53-79, February
1992.
- 4
-
Thomas E. Anderson, Michael D. Dahlin, Jeanna M. Neefe, David A. Patterson,
Drew S. Roselli, and Randolph Y. Wang.
Serverless network file systems.
In Proceedings of the Fifteenth ACM Symposium on Operating
System Principles, pages 109-126, Copper Mountain Resort, CO, U.S.A.,
December 1995. ACM SIGOPS.
>>>>>>.
- 5
-
N. Anerousis, R. Gopalakrishnan, C.R. Kalmanek, A.E. Kaplan, W.T. Marshall,
P.P. Mishra, P.Z. Onufryk, K.K. Ramakrishnan, and C.J. Sreenan.
TOPS: An architecture for telephony over packet networks.
IEEE Journal of Selected Areas in Communications, 17(1),
January 1999.
>>>>>>.
- 6
-
Oguz Angin, Andrew T. Campbell, Michael E. Kounavis, and Raymond R.-F. Liao.
The mobiware toolkit: Programmable support for adaptive mobile
networking.
IEEE Personal Communications Magazine, August 1998.
- 7
-
Guido Appenzeller, Kevin Lai, Petros Maniatis, Mema Roussopoulos, Edward
Swierk, Xinhua Zhao, and Mary Baker.
The mobile people architecture.
Technical Report CSL-TR-99-777, Stanford University, January 1999.
- 8
-
Joel F. Bartlett.
A NonStop kernel.
In Proceedings of the Eigth ACM Symposium on Operating Systems
Principles, pages 22-29, Pacific Grove, CA, U.S.A., December 1981. ACM
SIGOPS.
>>>>>>.
- 9
-
Forest Baskett, John H. Howard, and John T. Montague.
Task communication in DEMOS.
In Proceedings of the Sixth ACM Symposium on Operating Systems
Principles, pages 23-31, West Lafayette, IN, U.S.A., November 1977. ACM
SIGOPS.
- 10
-
Steven M. Bellovin and Michael Merrit.
Limitations of the kerberos authentication system.
Computer Communications Review, 20(5):119-132, October 1990.
>>>>>>.
- 11
-
A. Bensoussan, C. T. Clingen, and R. C. Daley.
The Multics Virtual Memory: Concepts and design.
Communications of the ACM, 15(5):308-318, May 1972.
>>>>>>.
- 12
-
Mark Berg, Marc van Kreveld, Mark de Overmars, and Otfried Schwarzkopf.
Computational Geometry by Example.
Unpublished, draft 0.1 edition, 1996.
- 13
-
Brian N. Bershad.
Practical considerations for non-blocking concurrent objects.
In Proceedings of the 13th International Conference on
Distributed Computing Systems, pages 264-273, Pittsburgh, PA, USA, May
1993. IEEE, IEEE Computer Society Press.
>>>>>>.
- 14
-
Brian N. Bershad, Thomas E. Anderson, Edward D. Lazowska, and Henry M. Levy.
Lightweight remote procedure call.
ACM Transactions on Computer Systems, 8(1):37-55, February
1990.
>>>>>>.
- 15
-
Brian N. Bershad, Stefan Savage, Przemysaw Pardyak, Emin Gün Sirer,
Marc E. Fiuczynski, David Becker, Craig Chamgers, and Susan Eggers.
Extensibility, safety and performance in the SPIN operating system.
In Proceedings of the Fifteenth ACM Symposium on Operating
System Principles, pages 267-284, Copper Mountain Resort, CO, U.S.A.,
December 1995. ACM SIGOPS.
>>>>>>.
- 16
-
Andrew Birrell, Greg Nelson, Susan Owicki, and Edward Wobber.
Network objects.
In Proceedings of the Fourteenth ACM Symposium on Operating
Systems Principles, pages 217-230, Asheville, NC, U.S.A., December
1993. ACM SIGOPS.
- 17
-
Andrew D. Birrell, Roy Levin, Roger M. Needham, and Michael D. Schroeder.
Grapevine: An exercise in distributed computing.
Communications of the ACM, 25(4):260-274, April 1982.
>>>>>>.
- 18
-
Andrew D. Birrell and Bruce Jay Nelson.
Implementing remote procedure calls.
ACM Transactions on Computer Systems, 2(1):39-59, February
1984.
>>>>>>.
- 19
-
Edouard Bugnion, Scott Devine, and Mendel Rosenblum.
Disco: Running commodity operating systems on scalable
multiprocessors.
In Proceedings of the Sixteenth ACM Symposium on Operating
Systems Principles, pages 143-156, Saint-Malo, France, December 1997. ACM
SIGOPS.
>>>>>>.
- 20
-
Michael Burrows and Martín Abadi.
A logic of authentication.
ACM Transactions on Computer Systems, 8(1):18-36, February
1990.
>>>>>>.
- 21
-
Ramón Cáceres and Liviu Iftode.
Improving the performance of reliable transport protocols in mobile
computing environments.
IEEE Journal on Selected Areas in Communications,
13(5):850-857, June 1995.
- 22
-
K. Mani Chandy and Eve M. Schooler.
Designing directories in distributed systems: A systematic framework.
In Proceedings of the Workshop on Multimedia and Collaborative
Environments, High Performance Distributed Computing Conference, Syracuse,
NY, U.S.A., August 1996.
>>>>>>.
- 23
-
John Chapin, Mendel Rosenblum, Scott Devine, Tirthankar Lahiri, Dan Teodosiu,
and Anoop Gupta.
Hive: Faults containment for shared-memory multiprocessors.
In Proceedings of the Fifteenth ACM Symposium on Operating
System Principles, pages 12-25, Copper Mountain Resort, CO, U.S.A.,
December 1995. ACM SIGOPS.
>>>>>>.
- 24
-
Peter M. Chen, Wee Teck Ng, Subhachandra Chandra, Christopher Aycock,
Gurushankar Rajamani, and David Lowell.
The Rio File Cache: Surviving operating system crashes.
In Proceedings of the Seventh International Conference on
Architectural Support for Programming Languages and Operating Systems
(ASPLOS-VII), pages 74-83, Cambridge, MA, U.S.A., October 1996. ACM
SIGPLAN.
>>>>>>.
- 25
-
David R. Cheriton and Kenneth J. Duda.
A caching model of operating system kernel functionality.
In Proceedings of the First Symposium on Operating Systems
Design and Implementation, pages 179-193. USENIX Association, November
1994.
- 26
-
David R. Cheriton and Timothy P. Mann.
Decentralizing a global naming service for improved performance and
fault tolerance.
ACM Transactions on Computer Systems, 7(2):147-183, May
1989.
>>>>>>.
- 27
-
Gihwan Cho.
A location management scheme supporting route optimization for mobile
hosts.
Journal of Network and Systems Management, 6(1), March 1998.
- 28
-
Gihwan Cho and Lindsay F. Marshall.
An efficient location and routing scheme for mobile computing
environments.
IEEE Journal on Selected Areas in Communications, 13(5), June
1995.
- 29
-
E. G. Jr. Coffman, M. J. Elphick, and A. Shoshani.
System deadlocks.
ACM Computing Surveys, 3(2):67-78, June 1971.
>>>>>>.
- 30
-
Microsoft Corporation.
Enterprise identity management within the digital nervous system.
On-line:
http://www.microsoft.com/windows/server/Eval/strategic/EIM.asp, July 1999.
>>>>>>.
- 31
-
R. C. Daley and J. B. Dennis.
Virtual memory, processes and sharing in MULTICS.
Communications of the ACM, 11(5):306-312, May 1968.
- 32
-
Peter B. Danzig, Katia Obraczka, and Anant Kumar.
An analysis of wide-area name server traffic: A study of the internet
domain name system.
In "Proceedings of the Conference on Communications Architecture
& Protocols (SIGCOMM '92)", pages 281-292, Baltimore, MD, U.S.A.,
August 1992. ACM SIGCOMM.
>>>>>>.
- 33
-
Mark Day, Sonu Aggarwal, Gordon Mohr, and Jesse Vincent.
Instant messaging / presence protocol requirements, February 2000.
Work in progress. >>>>>>.
- 34
-
Mark Day, Jonathan Rosenberg, and Hiroyasu Sugano.
A model for presence and instant messaging, February 2000.
Work in progress. >>>>>>.
- 35
-
Dorothy E. Denning and Peter J. Denning.
Data security.
ACM Computing Surveys, 11(3):227-249, September 1979.
>>>>>>.
- 36
-
Peter J. Denning.
Working sets, past and present.
IEEE Transactions on Software Engineering, 6(2):64-84, March
1980.
>>>>>>.
- 37
-
Christian Dreke.
Introduction to personal communication on the internet.
Intel Technology Journal, Q4, August 1999.
On-line:
http://developer.intel.com/technology/itj/q31999/articles/art_2.htm
>>>>>>.
- 38
-
Dawson R. Engler, M. Frans Kaashoek, and James O'Toole.
Exokernel: An operating system architecture for application-level
resource management.
In Proceedings of the Fifteenth ACM Symposium on Operating
System Principles, pages 251-266, Copper Mountain Resort, CO, U.S.A.,
December 1995. ACM SIGOPS.
- 39
-
R. J. Feiertag and E. I. Organick.
The MULTICS input/output system.
In Proceedings of the Third ACM Symposium on Operating Systems
Principles, pages 35-41, Palo Alto, CA, U.S.A., 1971. ACM SIGOPS.
>>>>>>.
- 40
-
Bryan Ford, Godmar Back, Greg Benson, Jay Lepreau, Albert Lin, and Olin
Shivers.
The flux oskit: A substrate for kernel and language research.
In Proceedings of the Sixteenth ACM Symposium on Operating
Systems Principles, pages 38-51, Saint-Malo, France, December 1997. ACM
SIGOPS.
- 41
-
Armando Fox, Steve Gribble, Eric A. Brewer, and Elan Amir.
Adapting to network and client variability via on-demand dynamic
distillation.
In Proceedings of the Seventh International Conference on
Architectural Support for Programming Languages and Operating Systems
(ASPLOS-VII), pages 160-170, Cambridge, MA, U.S.A., October 1996. ACM
SIGPLAN.
>>>>>>.
- 42
-
Christopher W. Fraser.
Automatic inference of models for statistical code compression.
In Proceedings of the ACM SIGPLAN 1999 Conference on
Programming Language Design and Implementation (PLDI), pages
242-246, Atlanta, GA, U.S.A., May 1999. ACM SIGPLAN.
>>>>>>.
- 43
-
David K. Gifford.
Weighted voting for replicated data.
In Proceedings of the Seventh ACM Symposium on
Operating System Principles, pages 150-162, Pacific Grove, CA,
U.S.A., December 1979. ACM SIGOPS.
>>>>>>.
- 44
-
Jim Gray.
The transaction concept: Virtues and limitations.
In Very Large Data Bases, 7th International Conference, pages
144-154, Cannes, France, September 1981. IEEE, IEEE Press.
- 45
-
Graham Hamilton, Michael L. Powell, and James G. Mitchell.
Subcontract: A flexible base for distributed programming.
In Proceedings of the Fourteenth ACM Symposium on Operating
Systems Principles, pages 80-93, Asheville, NC, U.S.A., December 1993.
ACM SIGOPS.
>>>>>>.
- 46
-
S. Hardcastle-Kille.
RFC 1484: Using the OSI directory to achieve user friendly naming
(OSI-DS 24 (v12)), July 1993.
Obsoleted by RFC1781 [62]. >>>>>>.
- 47
-
Norman Hardy.
The KeyKOS architecture.
Operating Systems Review, 19(4):8-25, October 1985.
- 48
-
John H. Hartman and John K. Ousterhout.
The Zebra striped network file system.
In Proceedings of the Fourteenth ACM Symposium on Operating
Systems Principles, pages 29-43, Asheville, NC, U.S.A., December 1993.
ACM SIGOPS.
>>>>>>.
- 49
-
Kieran Harty and David R. Cheriton.
Application-controlled physical memory using external page-cache
management.
In Proceedings of the Fifth International Conference on
Architectural Support for Programming Languages and Operating Systems
(ASPLOS-V), pages 187-199, Boston, MA, U.S.A., October 1992. ACM
SIGPLAN.
>>>>>>.
- 50
-
Roger Haskin, Yoni Malachi, Wayne Sawdon, and Gregory Chan.
Implementing remote procedure calls.
ACM Transactions on Computer Systems, 6(1):82-108, February
1988.
>>>>>>.
- 51
-
C. A. R. Hoare.
Monitors: An operating system structuring concept.
Communications of the ACM, 17(10):549-557, October 1974.
>>>>>>.
- 52
-
C. A. R. Hoare.
Communicating sequential processes.
Communications of the ACM, 21(8):666-677, August 1978.
>>>>>>.
- 53
-
Jon Inouye and Jim Binkley.
Physical media independence: System support for dynamically available
network interfaces.
Technical Report CSE-97-001, Department of Computer Science and
Engineering, Oregon Graduate Institute of Science and Technology, January
1997.
- 54
-
Jon Inouye, Jim Binkley, and Jonathan Walpole.
Dynamic network reconfiguration support for mobile computers.
In MOBICOM '97. Proceedings of the third annual ACM/IEEE
international conference on Mobile computing and networking, pages 13-22,
Budapest, Hungary, September 1997. ACM/IEEE.
- 55
-
John Ioannidis, Dan Duchamp, and Gerald Q. Maguire Jr.
IP-based protocols for mobile internetworking.
In Proceedings of the ACM SIGCOMM Symposium on
Communication, Architecture, and Protocols, volume 21, pages 235-245,
Zurich, Switzerland, September 1991. ACM SIGCOMM.
- 56
-
ITU-T.
Recommendation X.500: Data Networks and Open System
Communications - Directory.
International Telecommunication Union, 3rd:08/1997 edition, August
1997.
>>>>>>.
- 57
-
ITU-T.
Recommendation X.501: Data Networks and Open System
Communications - Directory: Models.
International Telecommunication Union, 3rd:08/1997 edition, August
1997.
>>>>>>.
- 58
-
Akinori Iwakawa, Shingo Fujimoto, and Dave Marvit.
IDentity Infrastructure Protocol (IDIP), April 2000.
Work in progress. >>>>>>.
- 59
-
Jan Jannink, Derek Lam, Jennifer Widom, Donald C. Cox, and Narayanan
Shivakumar.
Efficient and flexible location management techniques for wireless
communication systems.
In Proceedings of the Second Annual International Conference on
Mobile Computing and Networking (MOBICOM '96), pages 38-49, Rye, NY,
USA, November 1996. ACM.
>>>>>>.
- 60
-
M. Frans Kaashoek, Dawson R. Engler, Gregory R. Ganger, Héctor M.
Briceño, Russell Hunt, David Mazières, Thomas Pinckney, Robert Grimm,
John Jannotti, and Kenneth Mackenzie.
Application performance and flexibility on exokernel systems.
In Proceedings of the Sixteenth ACM Symposium on Operating
Systems Principles, pages 52-65, Saint-Malo, France, December 1997. ACM
SIGOPS.
- 61
-
Tsuyoshi 'Go' Kanai, Shingo Fujimoto, Katherine Bretz, Dave Marvit, and Yoji
Khoda.
Identity infrastructure and the extended individual.
White paper on-line: http://www.fla.com/idi-whitepaper-aug.html,
August 1998.
>>>>>>.
- 62
-
S. Kille.
RFC 1781: Using the OSI directory to achieve user friendly
naming, March 1995.
Obsoletes RFC1484 [46]. >>>>>>.
- 63
-
James J. Kistler and M. Satyanarayanan.
Disconnected operations in the Coda file system.
ACM Transactions on Computer Systems, 10(1):3-25, February
1992.
>>>>>>.
- 64
-
Steven R. Kleiman.
Vnodes: An architecture for multiple file system types in Sun UNIX.
In USENIX Summer 1986 Technical Conference Proceedings, pages
238-247, Atlanta, GA, U.S.A., 1986. USENIX.
>>>>>>.
- 65
-
Nancy P. Kronenberg, Henry M. Levy, and William D Strecker.
VAXclusters: A closely-coupled distributed system.
ACM Transactions on Computer Systems, 4(2):130-146, May
1986.
>>>>>>.
- 66
-
Derek Lam, Yingwei Cui, Donald C. Cox, and Jennifer Widom.
A Location Management Technique to Support Lifelong Numbering in
Personal Communications Services.
"ACM Mobile Computing and Communications Review", 2(1):27-35,
January 1998.
>>>>>>.
- 67
-
Butler W. Lampson.
Designing a global name service.
In Proceedings of the Fifth Annual ACM Symposium on Princiles
of Distributed Computing, pages 1-10, Calgary, AL, Canada, August 1986.
ACM.
>>>>>>.
- 68
-
Butler W. Lampson, Martín Abadi, Michael Burrows, and Edward Wobber.
Authentication in distributed systems: Theory and practice.
In Proceedings of the Thirteenth ACM Symposium on Operating
System Principles, pages 165-182, Pacific Grove, CA, U.S.A., October
1991. ACM SIGOPS, ACM Press.
>>>>>>.
- 69
-
Butler W. Lampson and David D. Redell.
Experiences with processes and monitors in Mesa.
Communications of the ACM, 23(2):105-117, February 1980.
>>>>>>.
- 70
-
Hugh C. Lauer.
Observations on the development of an operating system.
In Proceedings of the Eighth ACM Symposium on Operating
Systems Principles, pages 14-16, Pacific Grove, CA, U.S.A., December
1981. ACM SIGOPS.
- 71
-
Hugh C. Lauer and Roger M. Needham.
On the duality of operating systems structures.
Operating Systems Review, 13(2):3-19, April 1979.
>>>>>>.
- 72
-
Barbara Liskov, Sanjay Ghemawat, Robert Gruber, Paul Johnson, Liuba Shrira, and
Michael Williams.
Replication in the Harp file system.
In Proceedings of the Thirteenth ACM Symposium on Operating
System Principles, pages 226-238, Pacific Grove, CA, U.S.A., October
1991. ACM SIGOPS, ACM Press.
>>>>>>.
- 73
-
Gavin Lowe.
An attack on the Needham-Schroeder public-key authentication
protocol.
Information Processing Letters, 56(3):131-133, 10 November
1995.
>>>>>>.
- 74
-
Henry Massalin and Calton Pu.
Threads and input/output in the Synthesis kernel.
In Proceedings of the Twelfth ACM Symposium on Operating
Systems Principles, pages 191-200, Litchfield Park, AZ, U.S.A.,
December 1989. ACM SIGOPS.
- 75
-
Marshall K. McKusick, William N. Joy, Samuel J. Leffler, and Robert S. Fabry.
A fast file system for UNIX.
ACM Transactions on Computer Systems, 2(3):181-197, August
1984.
>>>>>>.
- 76
-
James G. Mitchell, Jonathan J. Gibbons, Graham Hamilton, Peter B. Kessler,
Yousef A. Khalidi, Panos Kougiouris, Peter W. Madany, Michael N. Nelson,
Michael L. Powell, and Sanjay R. Radia.
An overview of the spring system.
In Spring COMPCON 94 Digest of Papers, pages 122-131, San
Francisco, CA, U.S.A., February 1994. IEEE.
- 77
-
Paul V. Mockapetris and Kevin J. Dunlap.
Development of the domain name system.
In ACM SIGCOMM 1988 Symposium proceedings on Communications
architectures and protocols, pages 123-133, Stanford, CA, U.S.A.,
August 1988. ACM SIGCOMM.
>>>>>>.
- 78
-
Lily B. Mummert, Maria Ebling, and M. Satyanarayanan.
Exploiting weak connectivity for mobile file access.
In Proceedings of the Fifteenth ACM Symposium on Operating
System Principles, pages 143-155, Copper Mountain Resort, CO, U.S.A.,
December 1995. ACM/SIGOPS.
- 79
-
Andrew Myles, David B. Johnson, and Charles Perkins.
A mobile host protocol supporting route optimization and
authentication.
IEEE Journal on Selected Areas in Communications,
13(5):839-849, June 1995.
special issue on "Mobile and Wireless Computing Networks".
- 80
-
Roger M. Needham and Michael D. Schroeder.
Using encryption for authentication in large networks of computers.
Communications of the ACM, 21(12):993-999, December 1978.
>>>>>>.
- 81
-
Michael N. Nelson and Sanjay R. Radia.
A uniform name service for spring's UNIX environment.
In USENIX Winter 1994 Technical Conference Proceedings, pages
335-348, San Francisco, CA, January 1994. USENIX.
>>>>>>.
- 82
-
Gerald W. Neufeld.
Descriptive names in x.500.
In Proceedings of the ACM SIGCOMM Symposium on
Communication, Architecture, and Protocols, pages 64-71, Austin, TX,
U.S.A., September 1989. ACM SIGCOMM.
>>>>>>.
- 83
-
Peter G. Neumann.
What's in a name?
Communications of the ACM, 35(1):186, January 1992.
>>>>>>.
- 84
-
James W. O' Toole and David K. Gifford.
Names should mean What, not Where.
In 5th ACM Workshop on Distributed Systems. ACM, September
1992.
>>>>>>.
- 85
-
Brian Oki, Manfred Pfluegl, Alex Siegel, and Dale Skeen.
The information bus - an architecture for extensible distributed
systems.
In Proceedings of the Fourteenth ACM Symposium on Operating
Systems Principles, pages 58-68, Asheville, NC, U.S.A., December 1993.
ACM SIGOPS.
- 86
-
Randy Otte, Paul Patrick, and Mark Roy.
Understanding CORBA: the common object request broker
architecture.
Pretice Hall, Inc., Upper Saddle River, New Jersey 07458, USA, 1st
edition, 1996.
- 87
-
C. Partridge, T. Mendez, and W. Milliken.
RFC 1546: Host anycasting service, November 1993.
Status: INFORMATIONAL. >>>>>>.
- 88
-
Oren Patashnik.
Bibtexing.
An on-line manual on BibTeX, February 1988.
- 89
-
Charles Perkins, Andrew Myles, and David B. Johnson.
IMHP: A mobile host protocol for the internet.
Computer Networks And ISDN Systems, 27(3):479-491, 1994.
- 90
-
Charles E. Perkins, Andrew Myles, and David B. Johnson.
The internet mobile host protocol (IMHP).
In INET '94/JENC5, pages 642-1 - 642-9. Internet Society,
June 1994.
- 91
-
David T. Perkins.
Understanding SNMP MIBs.
Published on the World Wide Web, September 1993.
- 92
-
Larry L. Peterson.
The profile naming service.
ACM Transactions on Computer Systems, 6(4):341-364, November
1988.
>>>>>>.
- 93
-
Alan Pope.
The CORBA reference guide: understanding the common object
request broker architecture.
Addison Wesley Longman, Inc., One Jacob Way, Reading, Massachusetts
01867, USA, 1997.
- 94
-
Sanjay Radia, Peter Madany, and Michael L. Powell.
Persistence in the spring system.
In Proceedings of the Third International Workshop on Object
Orientation in Operating Systems, pages 12-23, Asheville, NC, U.S.A.,
December 1993. IEEE, IEEE Computer Society Press.
>>>>>>.
- 95
-
Sanjay Radia, Michael N. Nelson, and Michael L. Powell.
The spring name service.
Technical Report SMLI TR-93-16, Sun Microsystems Laboratories, Inc.,
M/S 29-01, 2550 Garcia Avenue, Mountain View, CA 94043, November 1993.
>>>>>>.
- 96
-
Sanjay R. Radia.
Naming policies in the spring system.
In Proceedings of IEEE Workshop on Services for Distributed
and Networked Environments, pages 164-171, Prague, Czech Republic, June
1994. IEEE, IEEE Computer Society Press.
>>>>>>.
- 97
-
Suchitra Raman and Steven McCanne.
A model, analysis, and protocol framework for soft state-based
communication.
In Proceedings of the ACM SIGCOMM Symposium on
Communication, Architecture, and Protocols, pages 15-25, Cambridge, MA,
U.S.A., September 1999. ACM SIGCOMM.
>>>>>>.
- 98
-
Dennis M. Ritchie and Ken Thompson.
The UNIX time-sharing system.
Communications of the ACM, 17(7):365-375, July 1974.
- 99
-
Mendel Rosenblum and John K. Ousterhout.
The design and implementation of a log-structured file system.
In Proceedings of the Thirteenth ACM Symposium on Operating
System Principles, pages 1-15, Pacific Grove, CA, U.S.A., October 1991.
ACM SIGOPS, ACM Press.
>>>>>>.
- 100
-
David S. H. Rosenthal.
Evolving the Vnode interface.
In USENIX Summer 1990 Technical Conference Proceedings, pages
107-117, Anaheim, CA, U.S.A., 1990. USENIX.
>>>>>>.
- 101
-
Mema Roussopoulos, Petros Maniatis, Kevin Lai, Guido Appenzeller, and Mary
Baker.
Person-level Routing in the Mobile People Architecture.
In Proceedings of the USENIX Symposium on Internet
Technologies and Systems, pages 165-176, Boulder, CO, U.S.A., October
1999. USENIX Association.
- 102
-
Sandberg Russel, David Goldberg, Steve Kleiman, Dan Walsh, and Bob Lyon.
Design and implementation of the Sun Network FIlesystem.
In USENIX Summer 1985 Technical Conference Proceedings, pages
119-130, Portland, OR, U.S.A., June 1985. USENIX.
>>>>>>.
- 103
-
Michael D. Schroeder, Andrew D. Birrell, and Roger M. Needham.
Experience with Grapevine: The growth of a distributed system.
ACM Transactions on Computer Systems, 2(1):3-23, February
1984.
>>>>>>.
- 104
-
Michael D. Schroeder and Jerome H. Saltzer.
A hardware architecture for implementing protection rings.
Communications of the ACM, 15(3):157-170, March 1972.
>>>>>>.
- 105
-
L. H. Seawright and R. A. MacKinnon.
VM/370 - a study of multiplicity and usefulness.
IBM Systems Journal, 18(1):4-17, 1979.
- 106
-
Alan Jay Smith.
Input/output optimization and disk architectures: A survey.
Performance and Evaluation, 1:104-117, 1981.
>>>>>>.
- 107
-
Jennifer G. Steiner, Clifford Neumann, and Jeffrey I. Schiller.
Kerberos: An authentication service for open network systems.
In USENIX Winter 1988 Technical Conference Proceedings, pages
191-202. USENIX, February 1988.
- 108
-
Mark Stemm.
Vertical handoffs in wireless overlay networks.
Master's thesis, Computer Science Division, Department of Electrical
Engineering and Computer Science, University of California at Berkeley,
Berkeley, CA, U.S.A., 1996.
- 109
-
W. Richard Stevens.
TCP/IP Illustrated, Volume 1.
Professional Computing Series. Addison-Wesley, 1st edition, 1994.
- 110
-
Michael Stonebraker.
Operating system support for database management.
Communications of the ACM, 24(7):412-418, July 1981.
>>>>>>.
- 111
-
Michael Stonebraker, Deborah DuBourdieux, and William Edwards.
Problems in supporting data base transactions in an operating system
transaction manager.
Operating Systems Review, 19(1):6-14, January 1985.
>>>>>>.
- 112
-
Madhusudhan Talluri, Mark D. Hill, and Yousef A. Khalidi.
A new page table for 64-bit address spaces.
In Proceedings of the Fifteenth ACM Symposium on Operating
System Principles, pages 184-200, Copper Mountain Resort, CO, U.S.A.,
December 1995. ACM SIGOPS.
>>>>>>.
- 113
-
David L. Tennenhouse, Jonathan M. Smith, W. David Sincoskie, David J.
Wetherall, and Gary J. Minden.
A survey of active network research.
IEEE Communications Magazine, 35(1):80-86, January 1997.
>>>>>>.
- 114
-
Fumio Teraoka, Kim Claffy, and Mario Tokoro.
Design, implementation, and evaluation of virtual internet protocol.
Technical Report SCSL-TR-92-003, Sony Computer Science Laboratory
Inc., 3-14-13 Higashi-gotanda, Shinagawa-ku, Tokyo, 141 Japan, March 1992.
- 115
-
Fumio Teraoka and Mario Tokoro.
Host migration transparency in IP networks: The VIP approach.
Technical Report SCSL-TR-93-001, Sony Computer Science Laboratory
Inc., 3-14-13 Higashi-gotanda, Shinagawa-ku, Tokyo, 141 Japan, January 1993.
- 116
-
Fumio Teraoka, Yasuhiko Yokote, and Mario Tokoro.
A network architecture providing host migration transparency.
Technical Report SCSL-TR-91-004, Sony Computer Science Laboratory
Inc., 3-14-13 Higashi-gotanda, Shinagawa-ku, Tokyo, 141 Japan, May 1991.
- 117
-
Amin Vahdat, Michael Dahlin, Anderson Thomas, and Amit Aggarwal.
Active names: Flexible location and transport of wide-area resources.
In Proceedings of the USENIX Symposium on Internet
Technologies and Systems, pages 151-164, Boulder, CO, U.S.A., October
1999. USENIX Association.
>>>>>>.
- 118
-
Steve Vinoski.
CORBA: Integrating diverse applications within distributed
heterogeneous environments.
IEEE Communications Magazine, 35(2), February 1997.
- 119
-
Bruce Walker, Gerald Popek, Robert English, Charles Kline, and Greg Thiel.
The LOCUS distributed operating system.
In Proceedings of the Ninth ACM Symposium on Operating Systems
Principles, pages 49-70, Bretton Woods, NH, U.S.A., October 1983. ACM
SIGOPS.
>>>>>>.
- 120
-
David C. M. Wood, Sean S. Coleman, and Michael F. Schwartz.
Fremont: A system for discovering network characteristics and
problems.
In USENIX Winter 1993 Technical Conference Proceedings, pages
335-348. USENIX, January 1993.
>>>>>>.
Bibliography
This document was generated using the
LaTeX2HTML translator Version 98.1p1 release (March 2nd, 1998)
Copyright © 1993, 1994, 1995, 1996, 1997,
Nikos Drakos,
Computer Based Learning Unit, University of Leeds.
The command line arguments were:
latex2html -no_navigation -show_section_numbers -local_icons -split 0 -dir /home/maniatis/public_html/Bibliography Bibliography.tex.
The translation was initiated by Petros Maniatis on 2000-06-20
Petros Maniatis
2000-06-20
 );
principals P and Q are entitled and justified to use a shared secret X
(
);
principals P and Q are entitled and justified to use a shared secret X
(
 ).
).